[Read Paper] Efficient Processing of Deep Neural Networks A Tutorial and Survey
Published:
by
SingularityKChen
![]() (Last updated:
)
(Last updated:
)
- Categories:
- ReadPaper 30
- Tags:
- DLA 19
- DNN 12
- Survey 2
- Tutorial 1
- Efficient Processing of Deep Neural Networks: A Tutorial and Survey
Efficient Processing of Deep Neural Networks: A Tutorial and Survey
This article focuses on:
- processing of DNN inference
- addressing the efficiency of the CONV layers
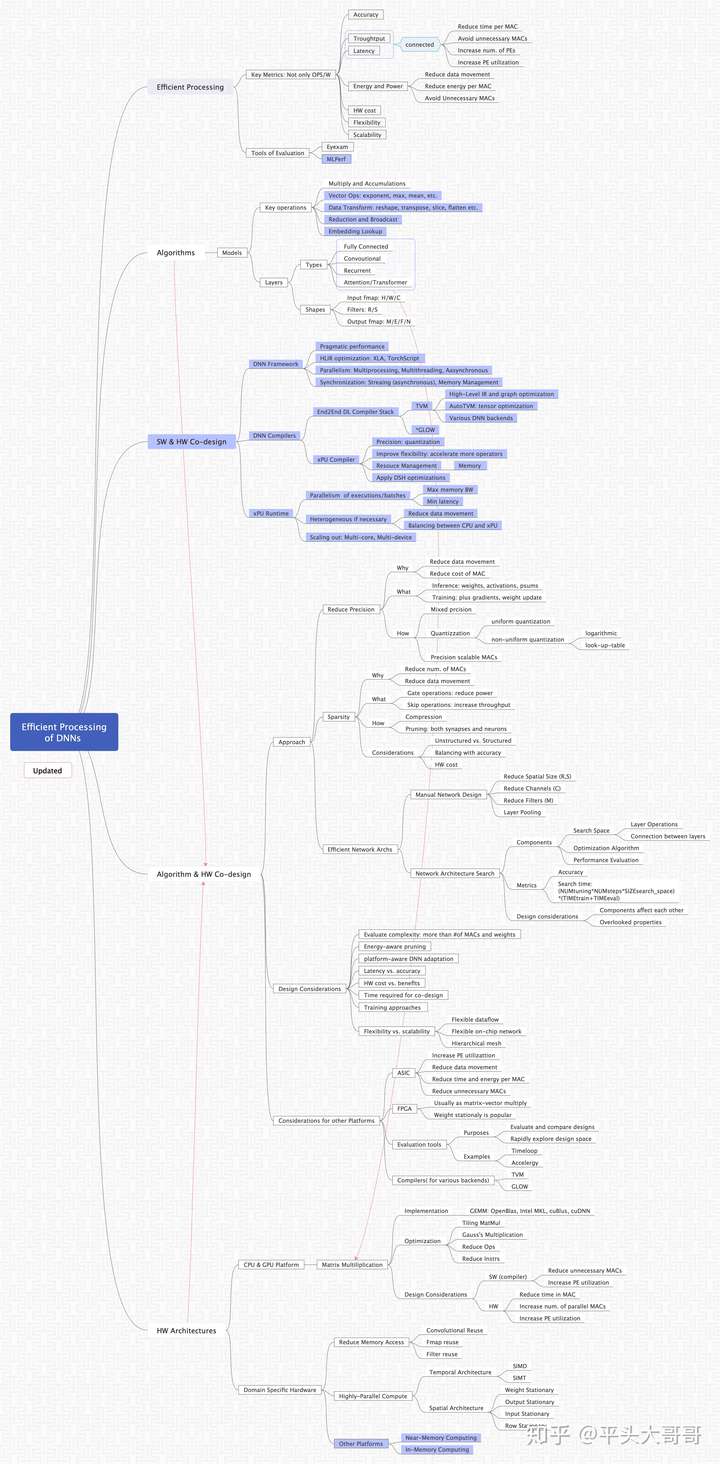
Below is a mind graph drew by Zhou Yongquan at this zhihu answer.
Or original picture here.
{kind=link}
Creating A System for Efficient DNN Processing
- Applications and specific computations requirements
- Understand and balance the important system metrics
- Accuracy
- Energy
- Throughput
- Hardware cost
- Accuracy
- Optimize DNN processing
- Joint hardware/software co-design
Temporal Architectures and Spatial Architectures

Temporal Architectures
- appear mostly in CPUs or GPUs
- employ a variety of techniques to improve parallelisms such as vectors (SIMD) or parallel threads (SIMT)
- use a centralized control for a large number of ALUs
- can only fetch data from the memory hierarchy
- cannot communicate directly with each other
- reduce the number of multiplications to increase throughput
Spatial Architectures
- use dataflow processing can pass data from one to another directly
- ALU can have its control logic and local memory
- how dataflows can increase data reuse from low-cost memories in the memory hierarchy to reduce energy consumption
Apply Computational Transforms to The Data
- Fast Fourier Transform (FFT) from O( $N^2_o$ $N^2_f$ ) to O($N^2_o$ $log_2N_o$)
- Winograd’s algorithm
- Strassen’s algorithm from O($N^3$) to O($N^{2.807}$)
Energy-Efficient Dataflow for Accelerators
Each MAC requires three memory reads:
- filter weight
- fmap activation
- partial sum
And one memory write: updated partial sum.
Different Dataflow:
- Weight Stationary (WS)
- Output Stationary (OS)
- No Local Reuse (NLR)
- Row Stationary (RS)
Near-Data Processing
We are supported to reduce data movement by moving compute and data closer. For example,
- Integrate the computation into the memory itself
- Bring the computation into the sensor where the data are first collected
DRAM
Avoid off-chip access by using high-density memories such as DRAMs. which can store tens of megabytes of weights and activations on-chip.
Also, with the help of through-silicon vias (TSVs), or 3-D memory, and HMC, HBM, the DRAM can be stacked on the top of the chip.
SRAM
Bring the compute into the memory.
Non-volatile Resistive Memories
- resistor’s conductance as the weight
- the voltage as the input
- the current as the output
- the addition is done by Kirchhoff’s current law
But it has some cons:
- suffers from the reduced precision as it needs ADC/DAC
- the array size is limited by the wires
- the IR drop along wire can degrade the read accuracy
Sensors
Need to move the computation into the analogy domain to avoid using the ADC within the sensor.
Co-Design of DNN Models And Hardware
Reduce Precision
And we can apply different precisions into weights and activations, different layers.
Reduce the precision of operations and operands:
- fixed point instead of floating-point
- reducing the bit-width: uniform quantization
- nonuniform quantization: map data to a smaller set of quantization levels
- log quantization
- learned quantization
- log quantization
- weight sharing
Reduced Number of Operations and Model Size
Reduce the number of operations and model size:
- compression: exploiting activation statistics
- network pruning
- compact network architectures: replace a large filter with a series of small filters
Benchmarking Metrics for DNN Evaluation and Comparison
Metrics for DNN Models
- The accuracy
- The network architecture of the model including the number of layers, filter sizes, number of filters and number of channels
- The number of weights: impact the storage requirement
- The number of MACs: potential throughput
Metrics for DNN Hardware
- The power and energy consumption
- The latency and throughput
- The cost of the chip: the size and type of memory, the amount of control logic
- For an FPGA,
- the specific device
- the utilization of resources such as:
- DSP
- BRAM
- LUT
- FF
- performance density
- GOPs/slice
- the utilization of resources such as:
- the specific device