[Weekly Review] 2020/01/27-02/02
Published:
by
SingularityKChen
![]() (Last updated:
)
(Last updated:
)
- Categories:
- WeeklyReview 81
2020/01/27-2020/02/02
This week I read a lot of materials related to the state-of-art chip architectures mainly from HPML 2019 and hot-chip 2019. Although the progress of FYP was a little slow this week, I figured out the dataflow and part of control logics of Eyeriss V2, which was rather tricky and time-costing, but does benefit for my next week's implementation. Also, I finished the translation of Chisel-Bootcamp chapter 3 from English to Chinese.
And next week, I'll back to the implementation of Eyeriss. And if I have time, I need to read the papers left weeks ago.
HotChip191
AMD2
Accelerated core IP
Chip-let architecture
High-speed coherent interconnects
System and software co-optimization
Continued technology scaling
Co-designing architecture and infrastructure1
Why?
-
Necessary due to End of Moore’s Law
-
Architect infrastructure for usability and scale
-
Leverage all areas of expertise
DLA Co-design:
ML research:
-
Computational requirements for cutting-edge models.
-
Input/output data feed rates
-
Types of operations to accelerate
-
Latency and bw requirements
-
Trains without loss scaling, unlike float 16
-
Latest computational requirements
-
Size and scope of models
ASIC:
- Small mantissa reduces multiplier power, area
Software:
-
Proper flexibility and programmability
-
Controllability
-
Same dynamic range as float 32, same Inf/NaN behavior
-
Programmability for parallelism infrastructure
Compilers:
- JIT code-gen & parallel IRs
Systems:
-
Power delivery, board space.
-
Board layout
-
Thermal limits
-
Liquid cooling
Data Center:
-
Cooling, buildability
-
Wiring and serviceability
-
Performance metrics
-
Space and network provisioning
-
Network requirements
-
Power delivery
System Co-design
Storage systems:
- high bandwidth disks, network
Accelerators:
- infeed & asynchronous abstractions
Software:
- high throughput, software pipelining, horizontal scaling.
NVIDIA3
Network-on-Package and Network-on-Chip
Use GRS for inter-chip communication
Tiled architecture with distributed memory
Scalable DL inference accelerator
Scaling DL inference across NoP/NoC
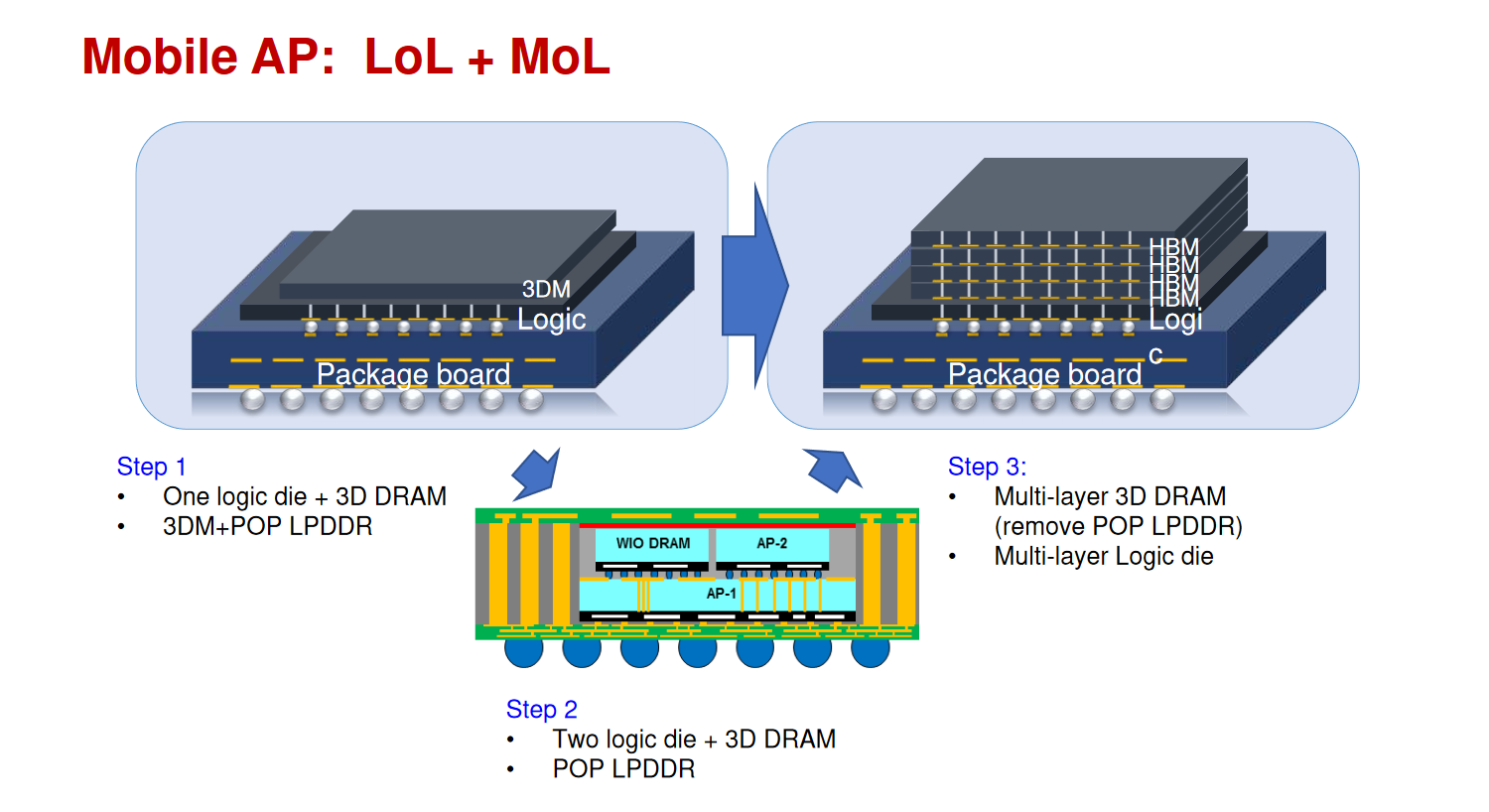
HUAWEI4
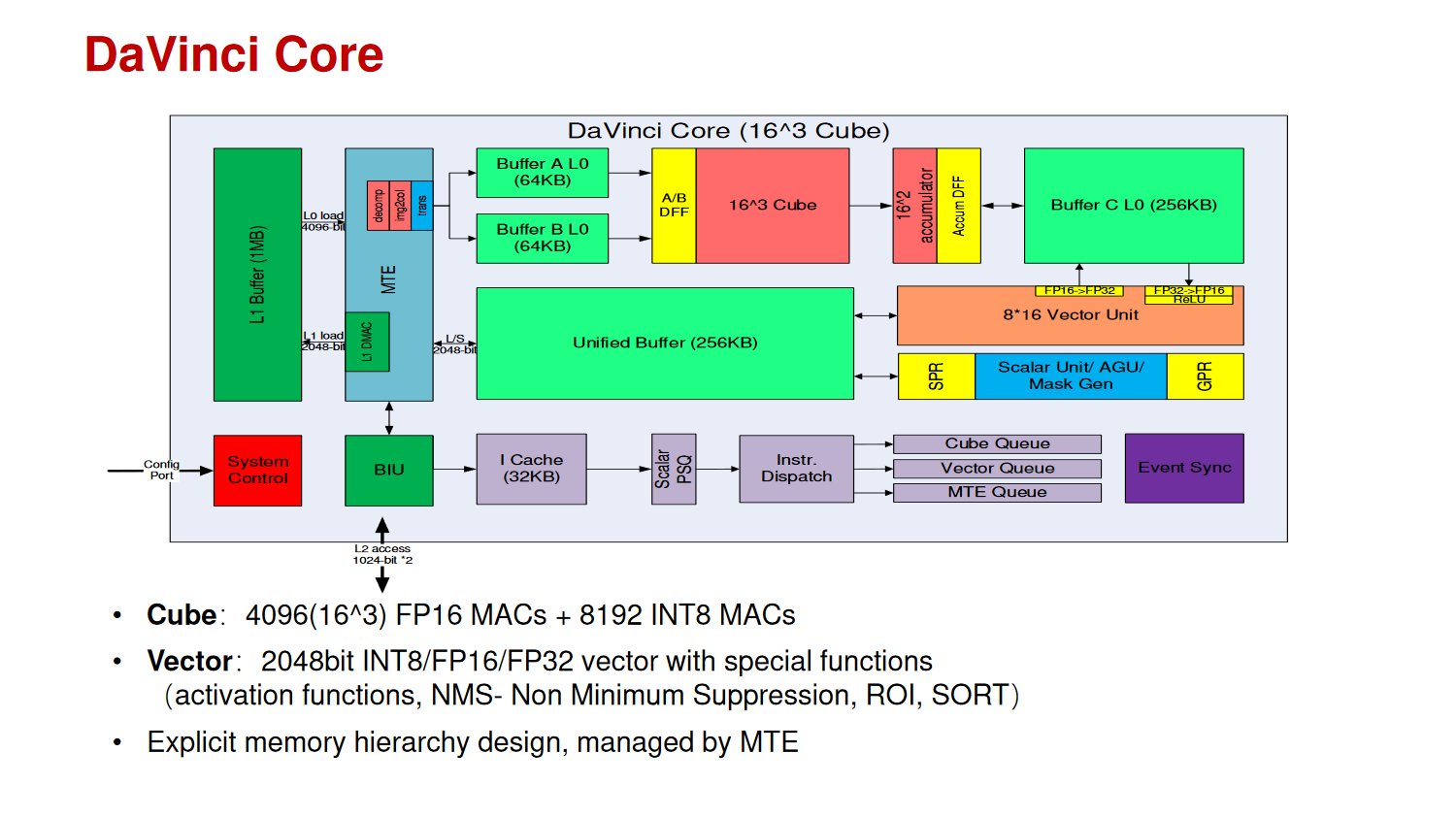
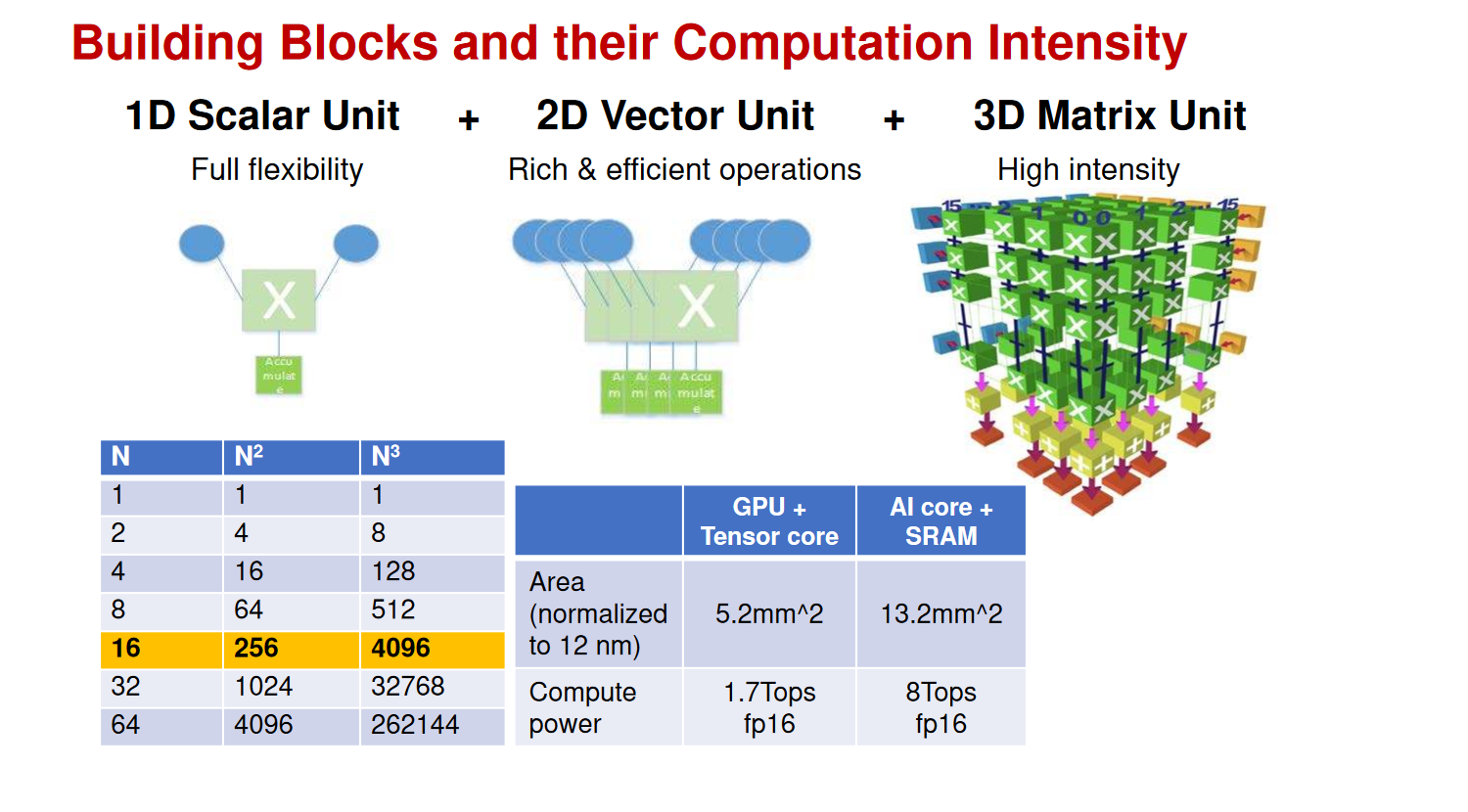
1D Scalar Unit + 2D Vector Unit + 3D Matrix Unit + 3DSRAM
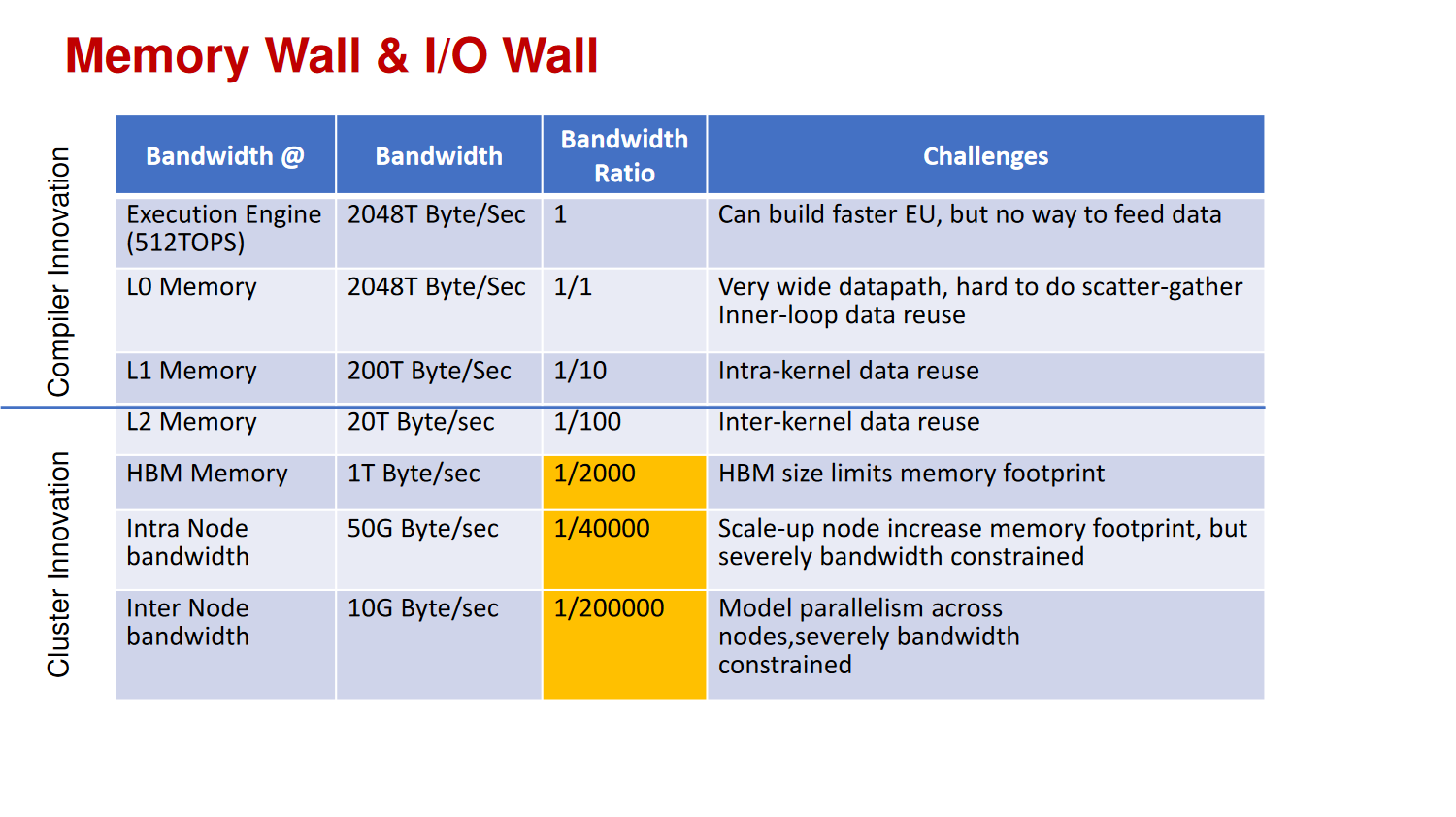
Memory Wall & I/O Wall
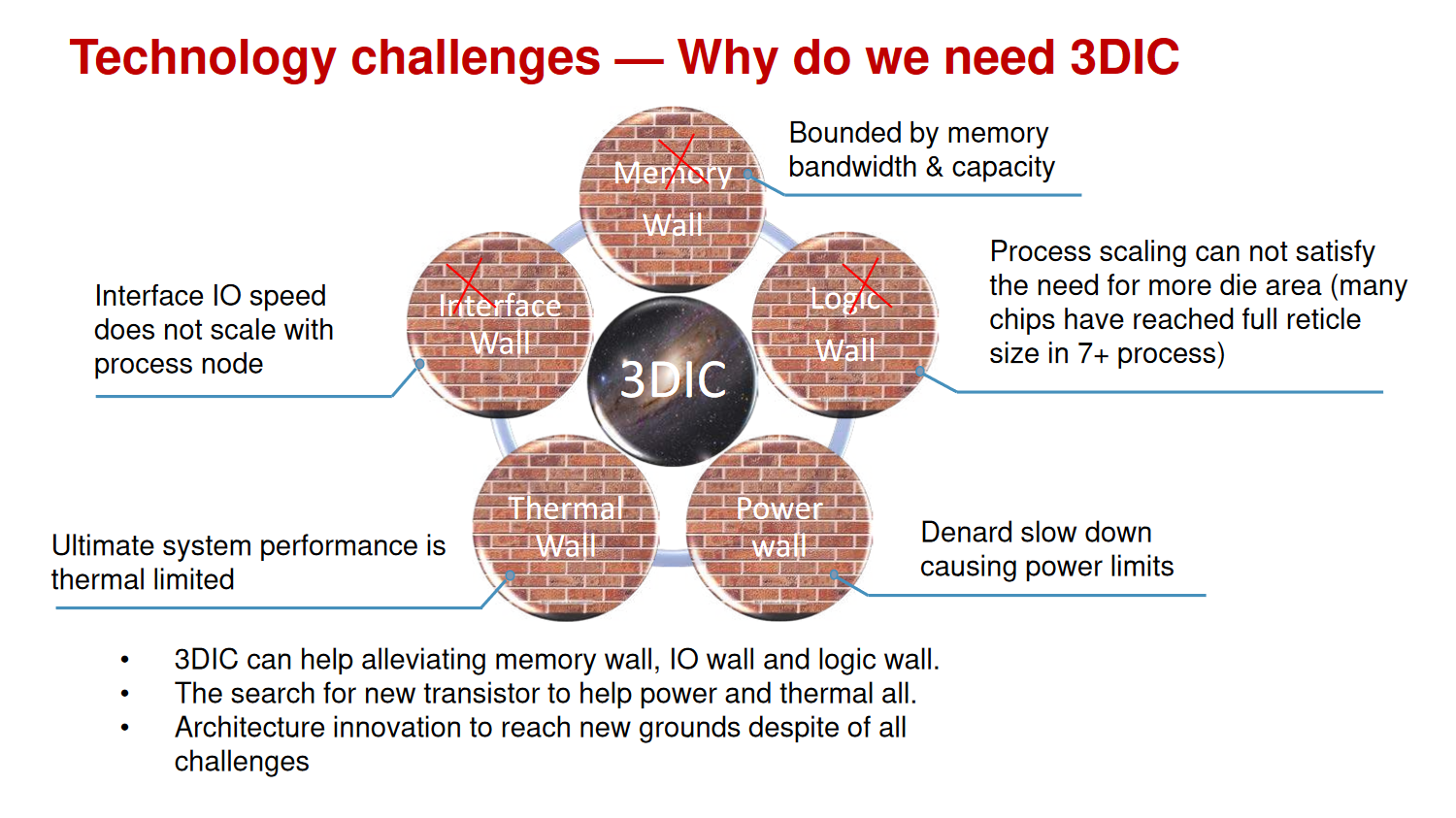
3D IC to alleviate memory wall, IO wall and logic wall
Ayar Labs5
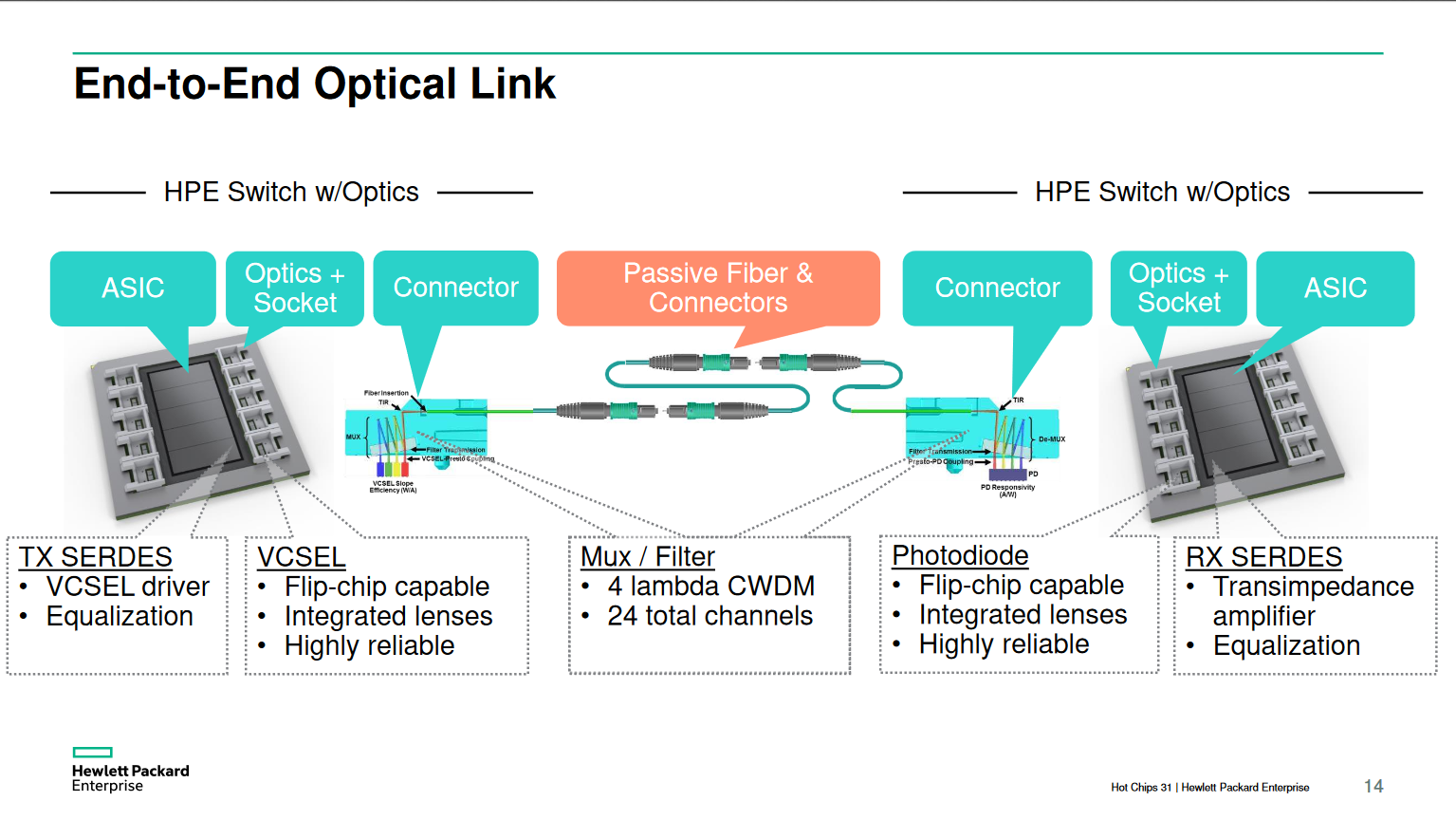
Chip-to-chip communications requires photonics to overcome I/O bottleneck
Emerging chip-let ecosystem offers opportunity for in-package optics
In -package optics fundamentally breaks the traditional bandwidth-distance trade-off and supports new high-performance computer architectures
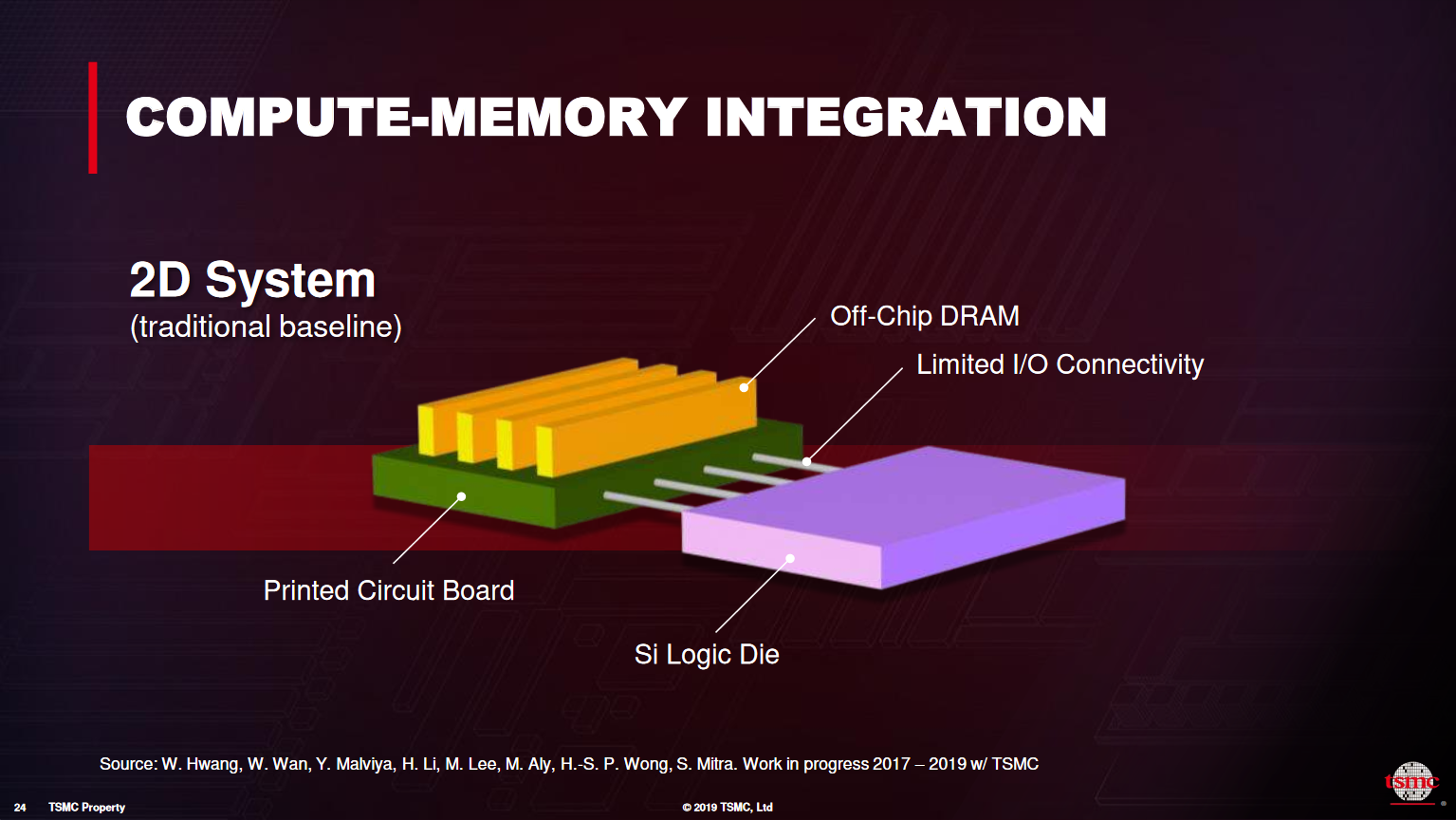
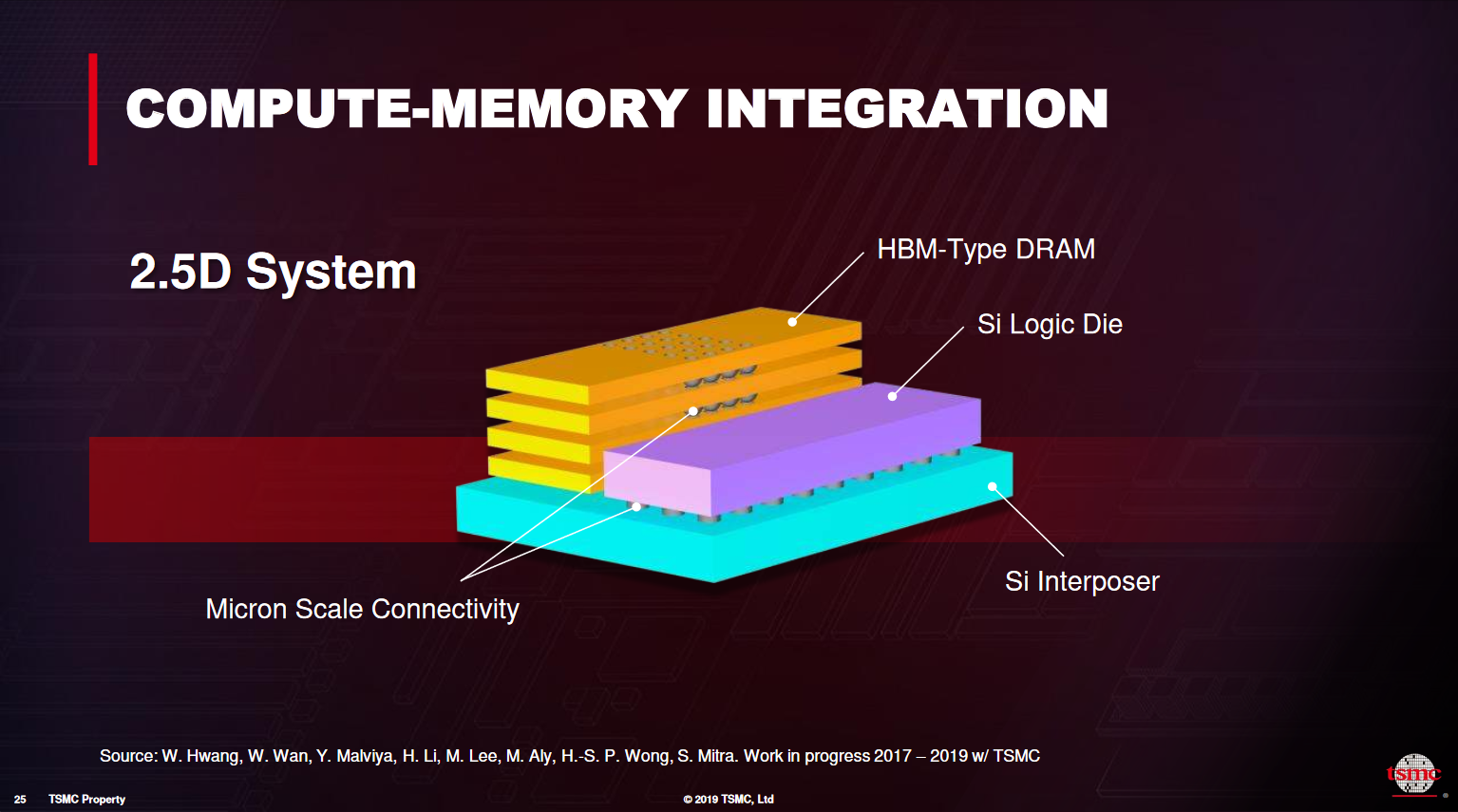
TSMC6
EoML: end of Moore's Law

COMPUTE-MEMORY INTEGRATION
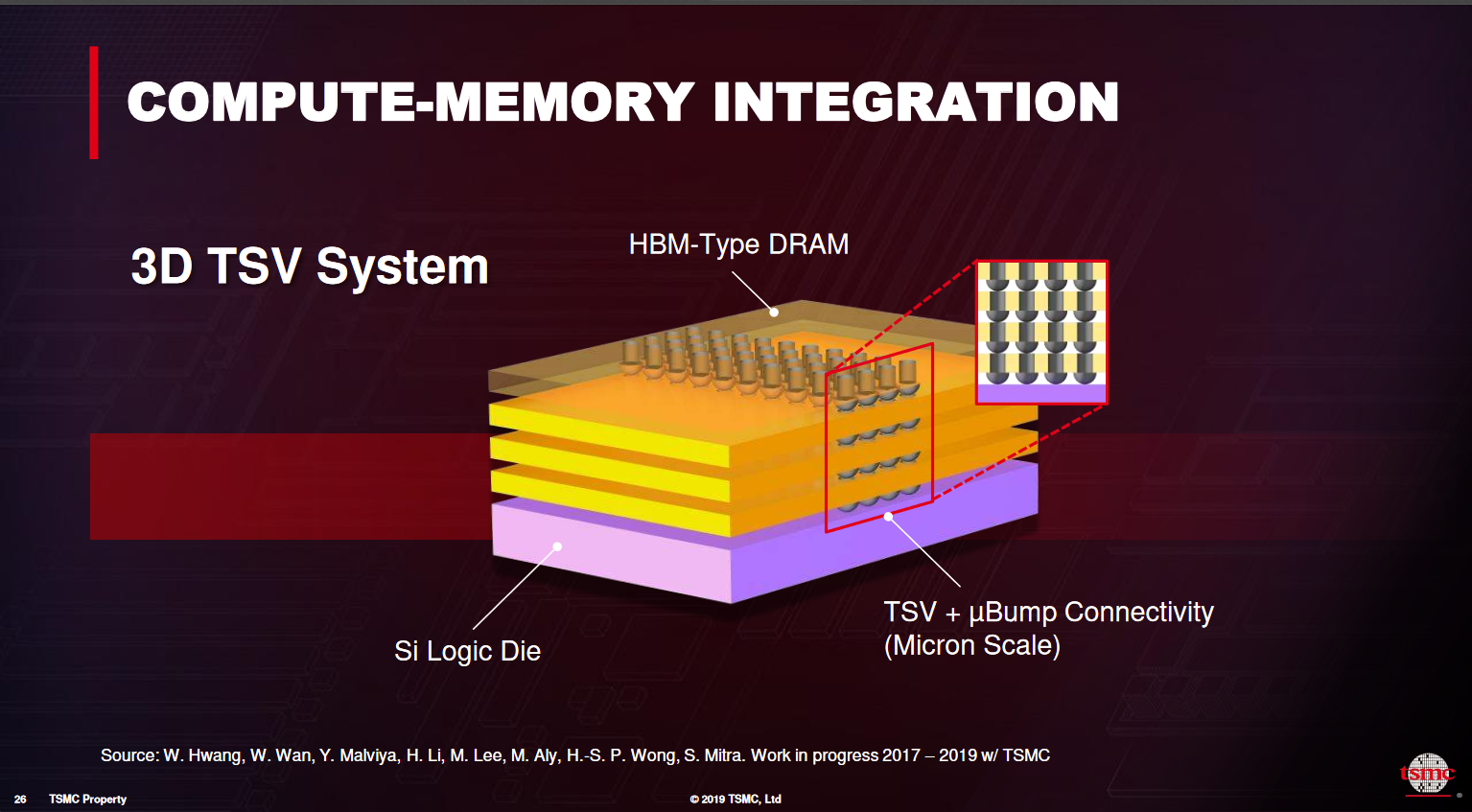
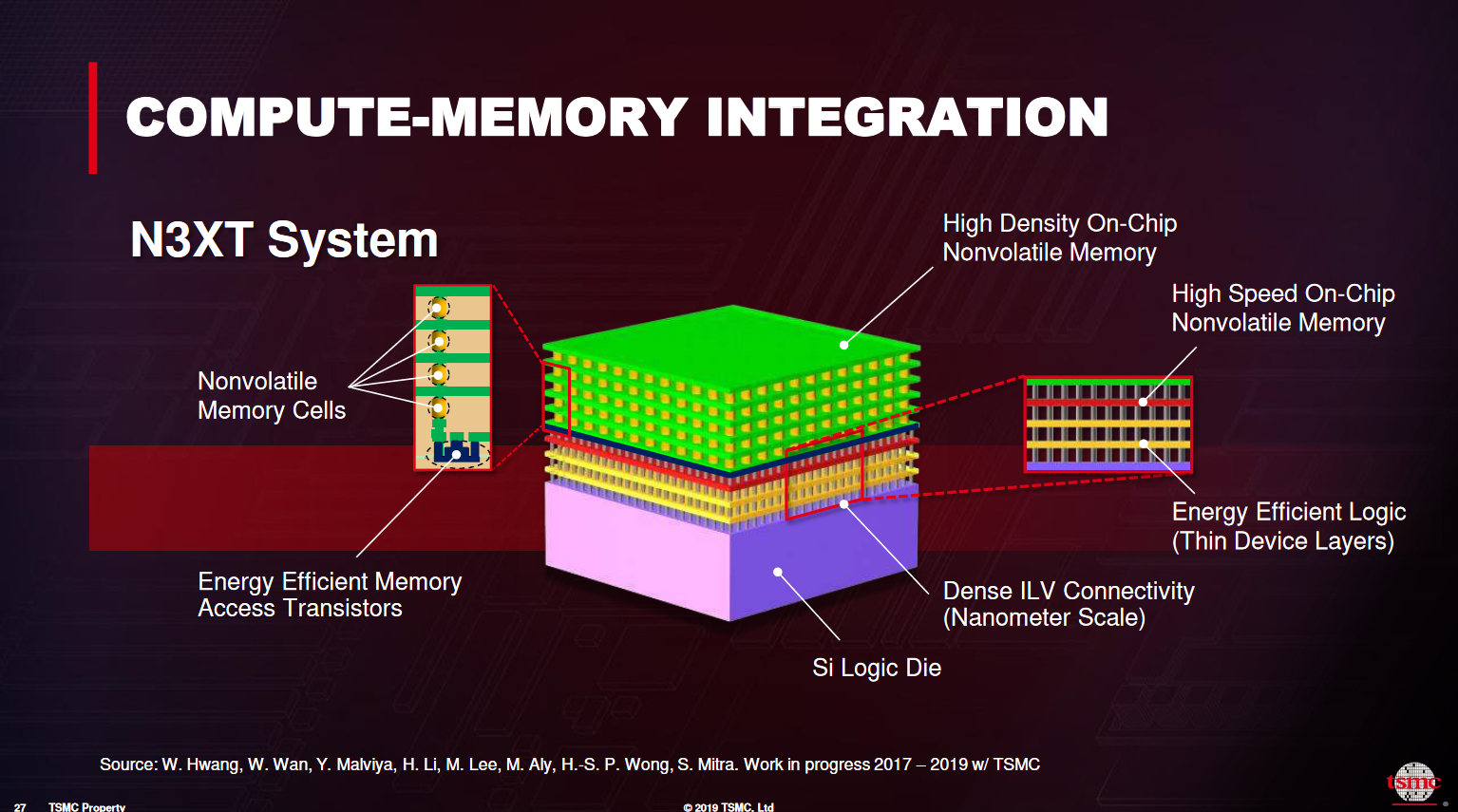
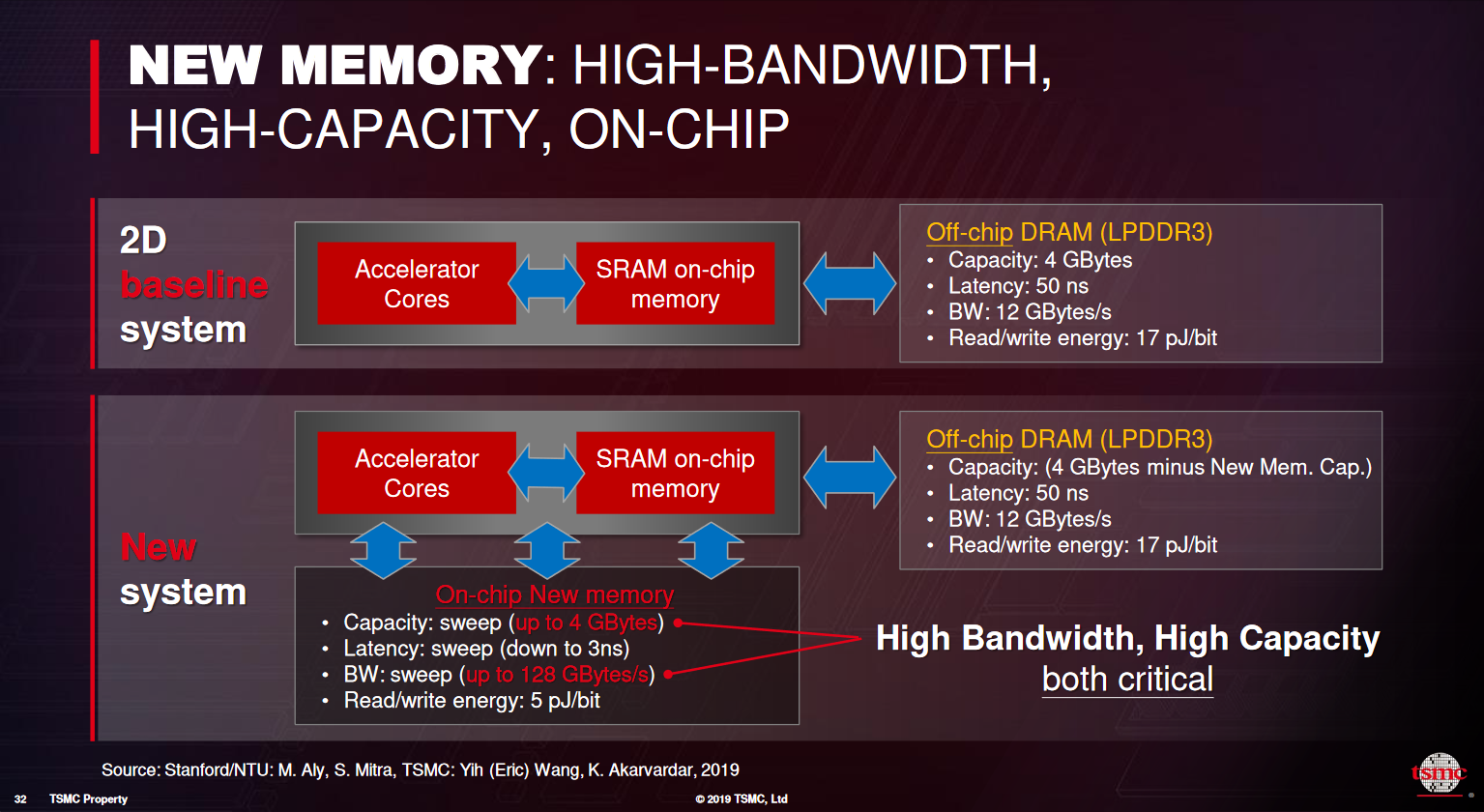
NVIDIA7

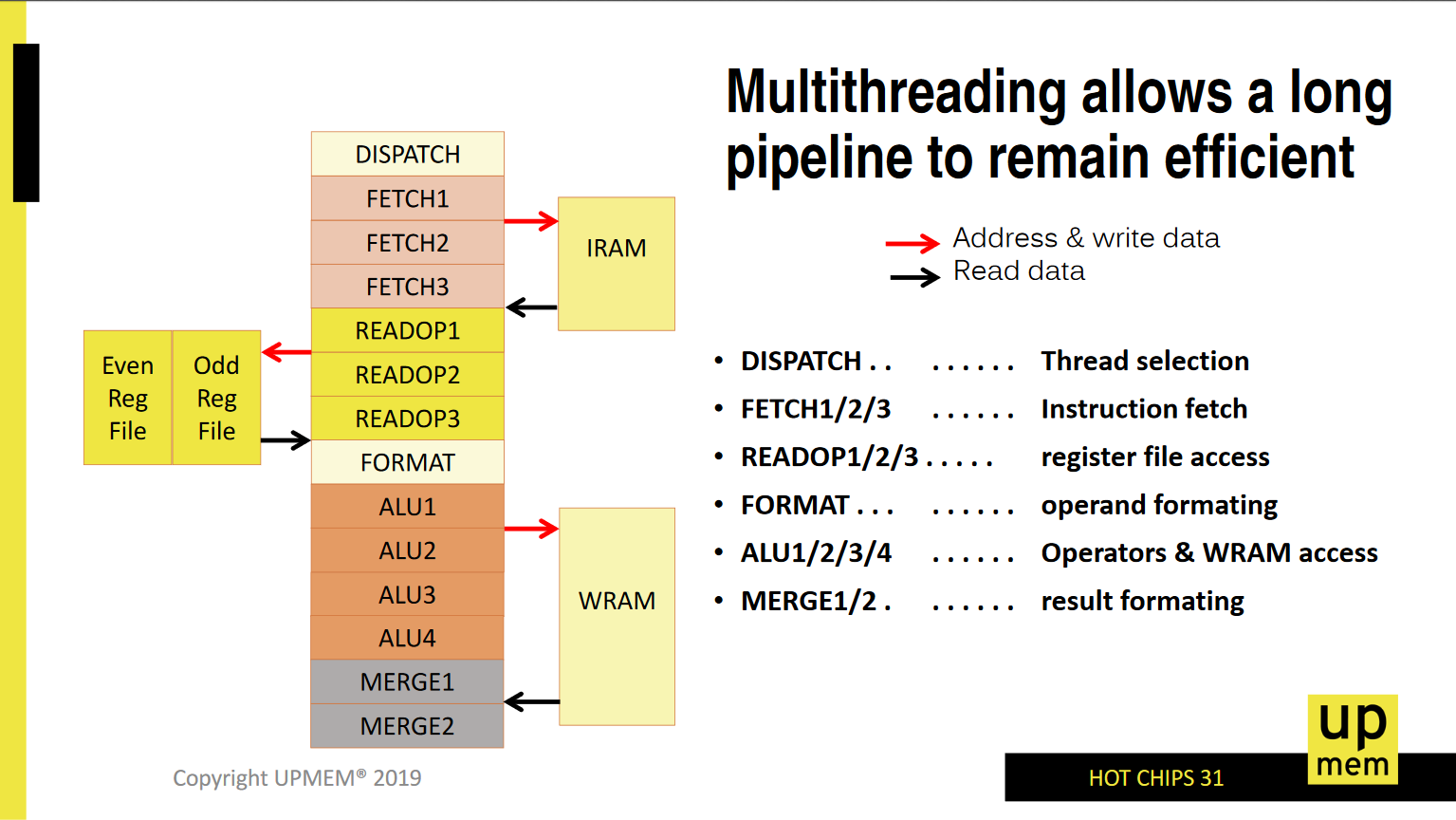
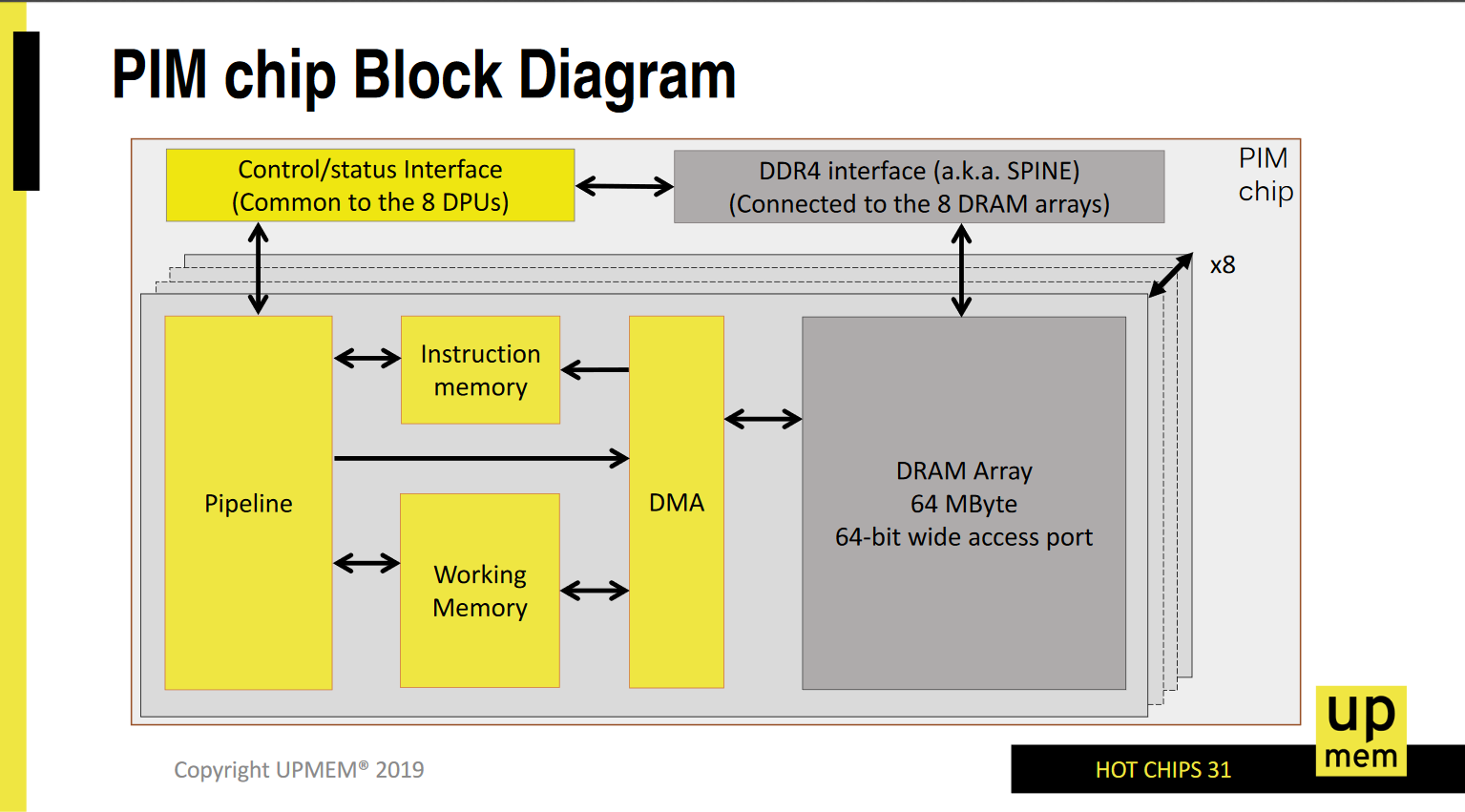
UPMEM8
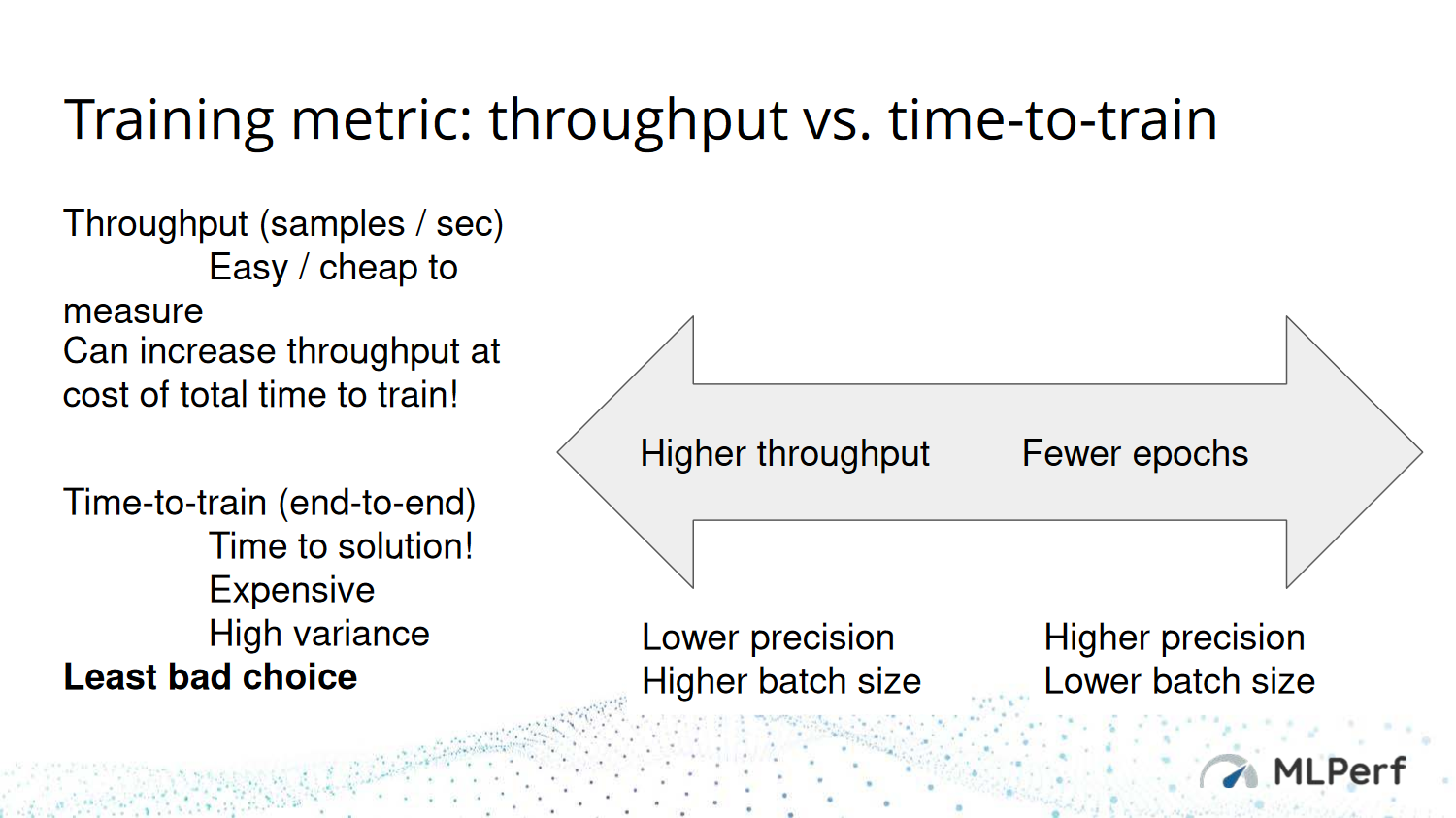
MLPerf9
Training Metric



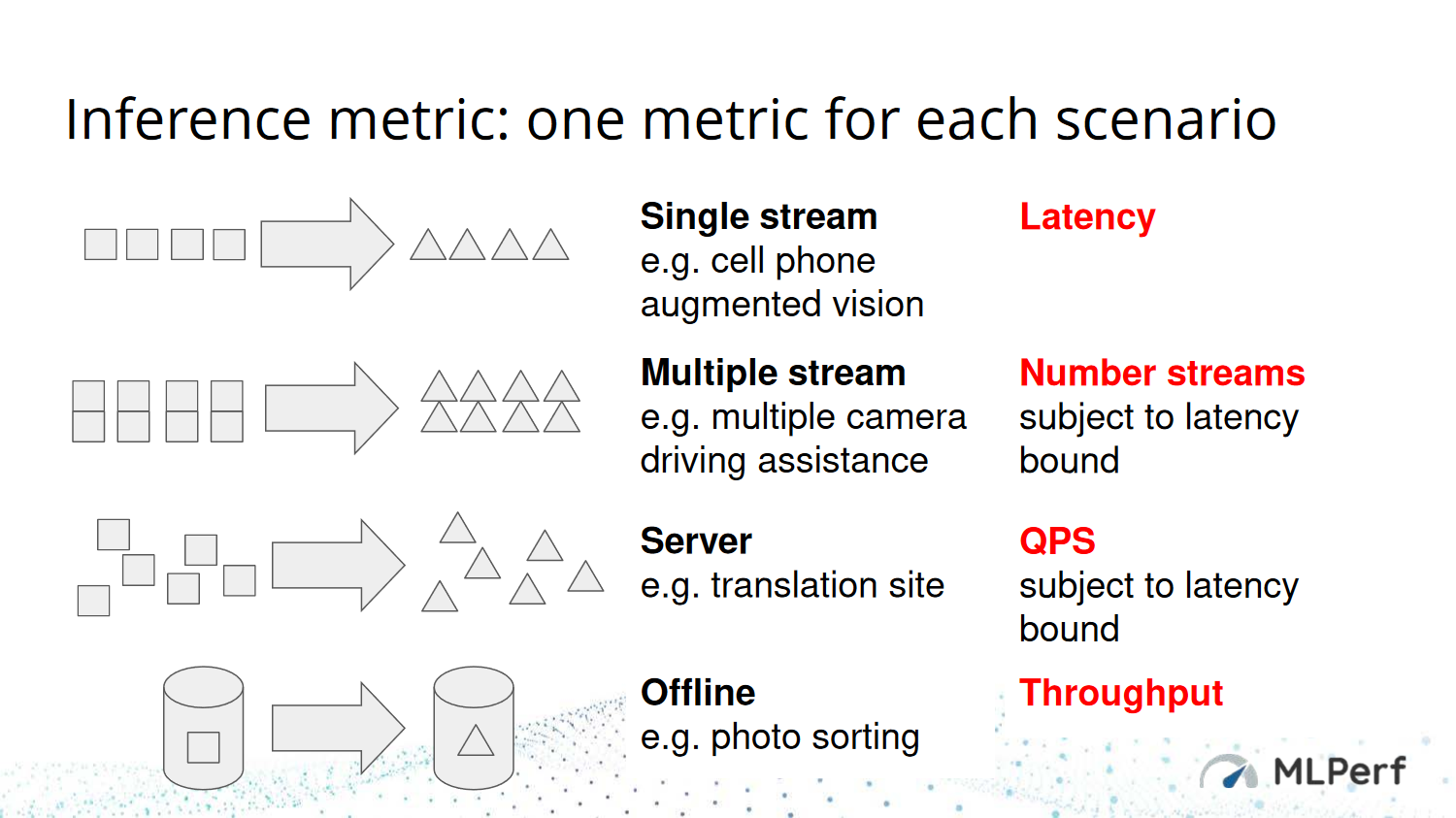
Inference Metric
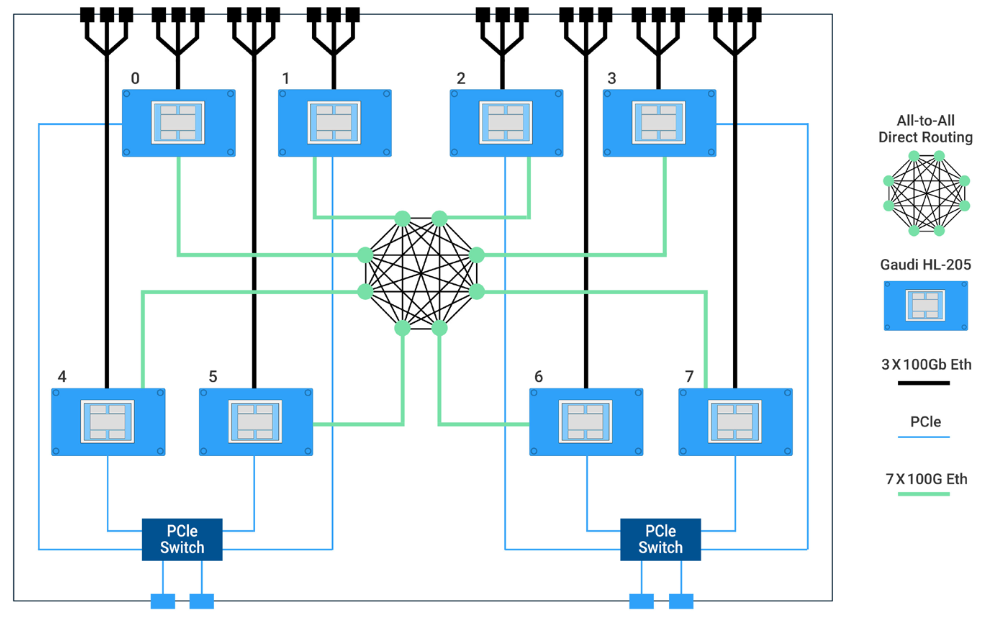
habana 10 11 12
Designed to scale
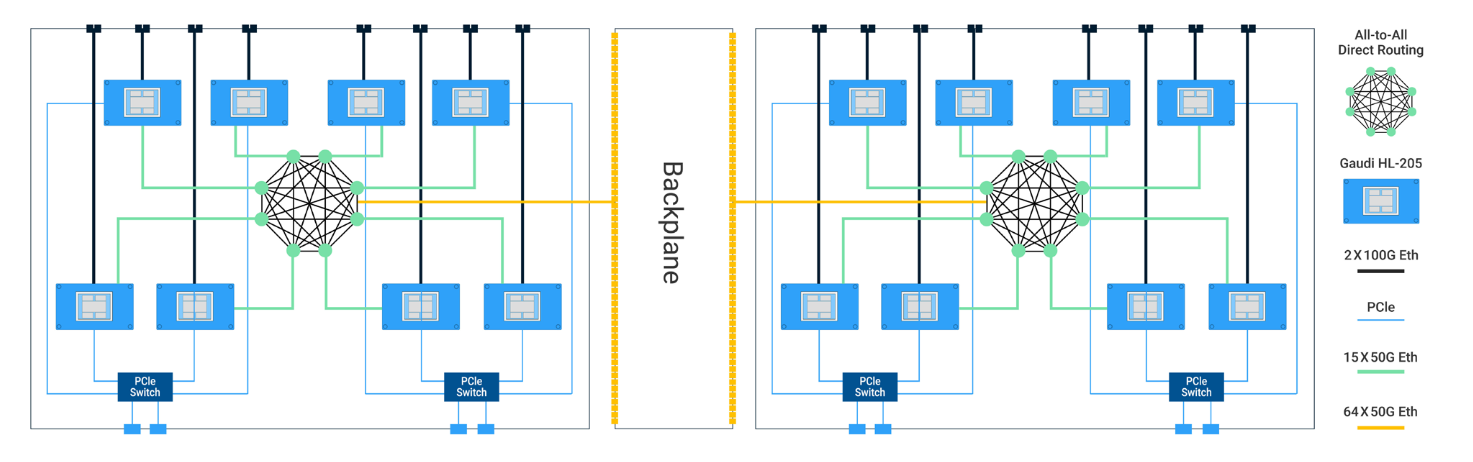
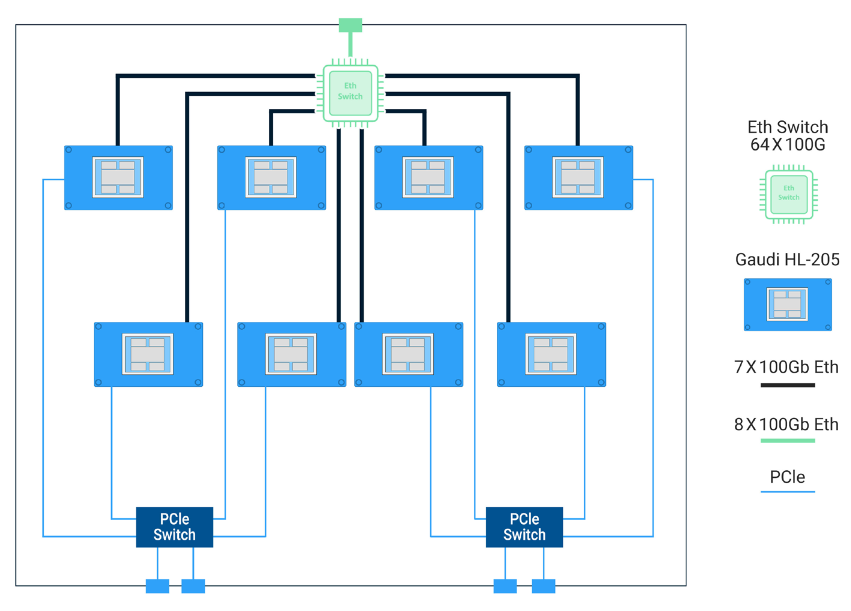
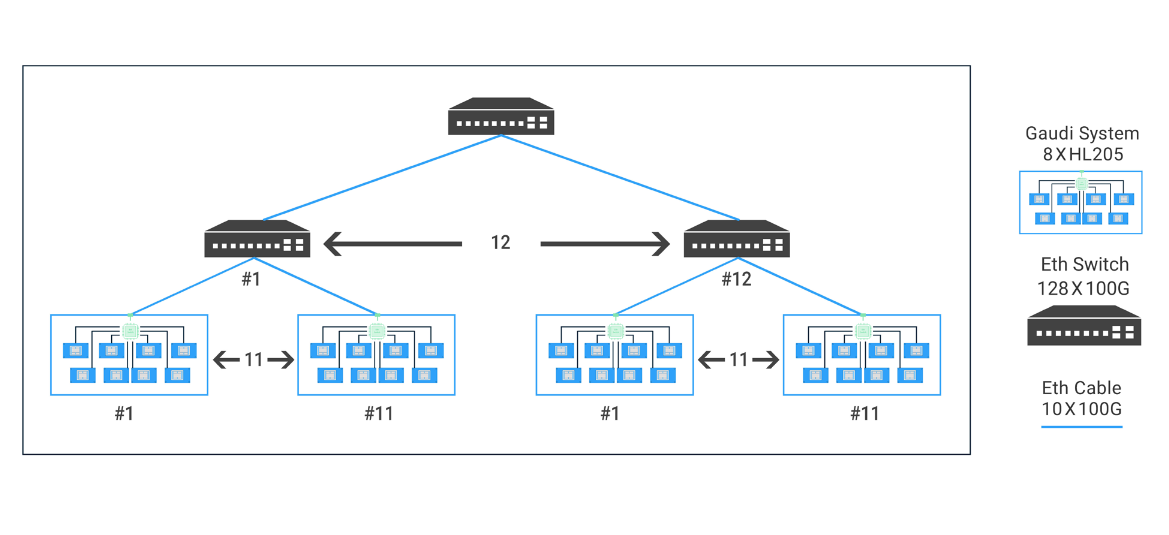
Current HPC Challenges
Large message collective communication and reductions10
Limited network bandwidth11
Parallel data access and computation11
Low latency (in inference)12
Most DL frameworks are optimized for single-node training10
Support different DNN models and layers12
Fully utilize HPC clusters10
Memory Wall & I/O Wall4
New features in Improving
Utilize photonics to overcome network BW bottleneck5
Co-design the support at runtime level and exploit it at the DL framework level10
Distributed (Parallel) Training10
Platform-aware compression and quantization
Dynamic adaptive resource management15
Software environment with a subset of hardware platform
Reference of this week
-
“HC31 (2019),” Hot Chips: A Symposium on High Performance Chips, 18-Aug-2019. [Online]. Available: https://www.hotchips.org/archives/2010s/hc31/. [Accessed: 31-Jan-2020]. ↩ ↩2
-
L. Su, “Delivering the Future of High-Performance Computing,” in 2019 IEEE Hot Chips 31 Symposium (HCS), 2019, pp. 1–43, doi: 10.1109/HOTCHIPS.2019.8875685. ↩
-
R. Venkatesan et al., “A 0.11 PJ/OP, 0.32-128 Tops, Scalable Multi-Chip-Module-Based Deep Neural Network Accelerator Designed with A High-Productivity vlsi Methodology,” in 2019 IEEE Hot Chips 31 Symposium (HCS), 2019, pp. 1–24, doi: 10.1109/HOTCHIPS.2019.8875657. ↩
-
H. Liao, J. Tu, J. Xia, and X. Zhou, “DaVinci: A Scalable Architecture for Neural Network Computing,” in 2019 IEEE Hot Chips 31 Symposium (HCS), 2019, pp. 1–44, doi: 10.1109/HOTCHIPS.2019.8875654. ↩ ↩2
-
M. Wade, “TeraPHY: A Chiplet Technology for Low-Power, High-Bandwidth in-Package Optical I/O,” in 2019 IEEE Hot Chips 31 Symposium (HCS), 2019, pp. i–xlviii, doi: 10.1109/HOTCHIPS.2019.8875658. ↩ ↩2
-
H.-S. P. Wong, R. Willard, and I. K. Bell, “IC Technology – What Will the Next Node Offer Us?,” in 2019 IEEE Hot Chips 31 Symposium (HCS), 2019, pp. 1–52, doi: 10.1109/HOTCHIPS.2019.8875692. ↩
-
J. Burgess, “RTX ON – The NVIDIA TURING GPU,” in 2019 IEEE Hot Chips 31 Symposium (HCS), 2019, pp. 1–27, doi: 10.1109/HOTCHIPS.2019.8875651. ↩
-
F. Devaux, “The true Processing In Memory accelerator,” in 2019 IEEE Hot Chips 31 Symposium (HCS), 2019, pp. 1–24, doi: 10.1109/HOTCHIPS.2019.8875680. ↩
-
P. Mattson, “ML Benchmark Design Challenges,” in 2019 IEEE Hot Chips 31 Symposium (HCS), 2019, pp. 1–36, doi: 10.1109/HOTCHIPS.2019.8875660. ↩
-
Habana Labs Ltd., “Habana Gaudi Training Platform whitepaper.” Jun-2019. ↩ ↩2 ↩3 ↩4 ↩5 ↩6
-
E. Medina, “[Habana Labs presentation],” in 2019 IEEE Hot Chips 31 Symposium (HCS), 2019, pp. 1–29, doi: 10.1109/HOTCHIPS.2019.8875670. ↩ ↩2 ↩3
-
“Training,” Habana. [Online]. Available: https://habana.ai/training/. [Accessed: 01-Feb-2020]. ↩ ↩2 ↩3
-
“HPML 2019: HIGH PERFORMANCE MACHINE LEARNING.” [Online]. Available: https://hpml2019.github.io/#keynote. [Accessed: 28-Jan-2020]. ↩
-
J. Keuper and F.-J. Preundt, “Distributed Training of Deep Neural Networks: Theoretical and Practical Limits of Parallel Scalability,” in 2016 2nd Workshop on Machine Learning in HPC Environments (MLHPC), 2016, pp. 19–26, doi: 10.1109/MLHPC.2016.006. ↩
-
V. Sze, Y.-H. Chen, T.-J. Yang, and J. S. Emer, “Efficient Processing of Deep Neural Networks: A Tutorial and Survey,” Proc. IEEE, vol. 105, no. 12, pp. 2295–2329, Dec. 2017, doi: 10.1109/JPROC.2017.2761740. ↩