[Weekly Review] 2020/02/03-09
Published:
by
SingularityKChen
![]() (Last updated:
)
(Last updated:
)
- Categories:
- WeeklyReview 81
2020/02/16-22
This week I read two papers:
- FPGA/DNN Co-Design: An Efficient Design Methodology for IoT Intelligence on the Edge;
- BitFlow: Exploiting Vector Parallelism for Binary Neural Networks on CPU;
Also, I continued the survey of MLforHPC.
Chisel Syntax
Transferring data type in generators
class ClusterCommonCtrlIO[T1:< Data, T2:< Data](dataType1: T1, dataType2: T2) extends Bundle {
val inDataSel: T1 = Output(dataType1)
val outDataSel: T2 = Output(dataType2)
}
class IactClusterIO[T1, T2](dataType1: T1, dataType2: T2, portNum: Int, addrWidth: Int, dataWidth: Int, addrLenWidth: Int, dataLenWidth: Int) extends Bundle {
val dataPath: Vec[ClusterAddrWithDataCommonIO] = Vec(portNum, new ClusterAddrWithDataCommonIO(addrWidth, dataWidth, addrLenWidth, dataLenWidth)) // output bits and valid
val ctrlPath = new ClusterCommonCtrlIO[T1, T2](dataType1, dataType2)
}
class IactRouterIO extends Bundle with ClusterConfig {
val outIOs = new IactClusterIO(UInt(2.W), UInt(2.W), iactPortNum, iactAddrWidth, iactDataWidth, commonLenWidth, commonLenWidth)
val inIOs: IactClusterIO[UInt, UInt] = Flipped(new IactClusterIO(UInt(2.W), UInt(2.W), iactPortNum, iactAddrWidth, iactDataWidth, commonLenWidth, commonLenWidth))
}
class PEAndRouterIO extends Bundle with ClusterConfig {
val iactCluster: IactClusterIO[Bool, UInt] = Flipped(new IactClusterIO[Bool, UInt](Bool(), UInt(2.W), iactRouterNum, iactAddrWidth, iactDataWidth, commonLenWidth, commonLenWidth))
}
Neural Network
Architecture
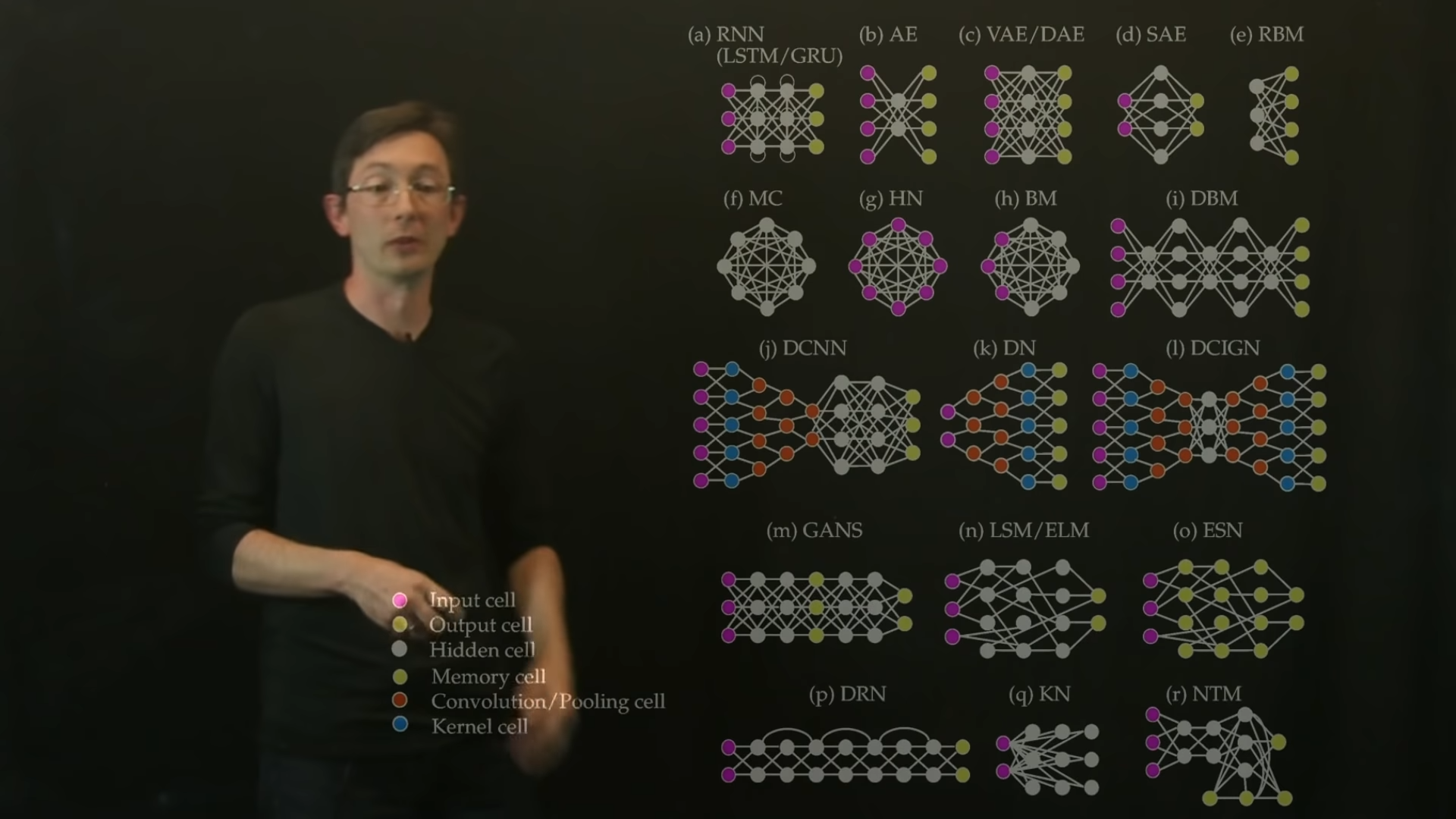
Overview
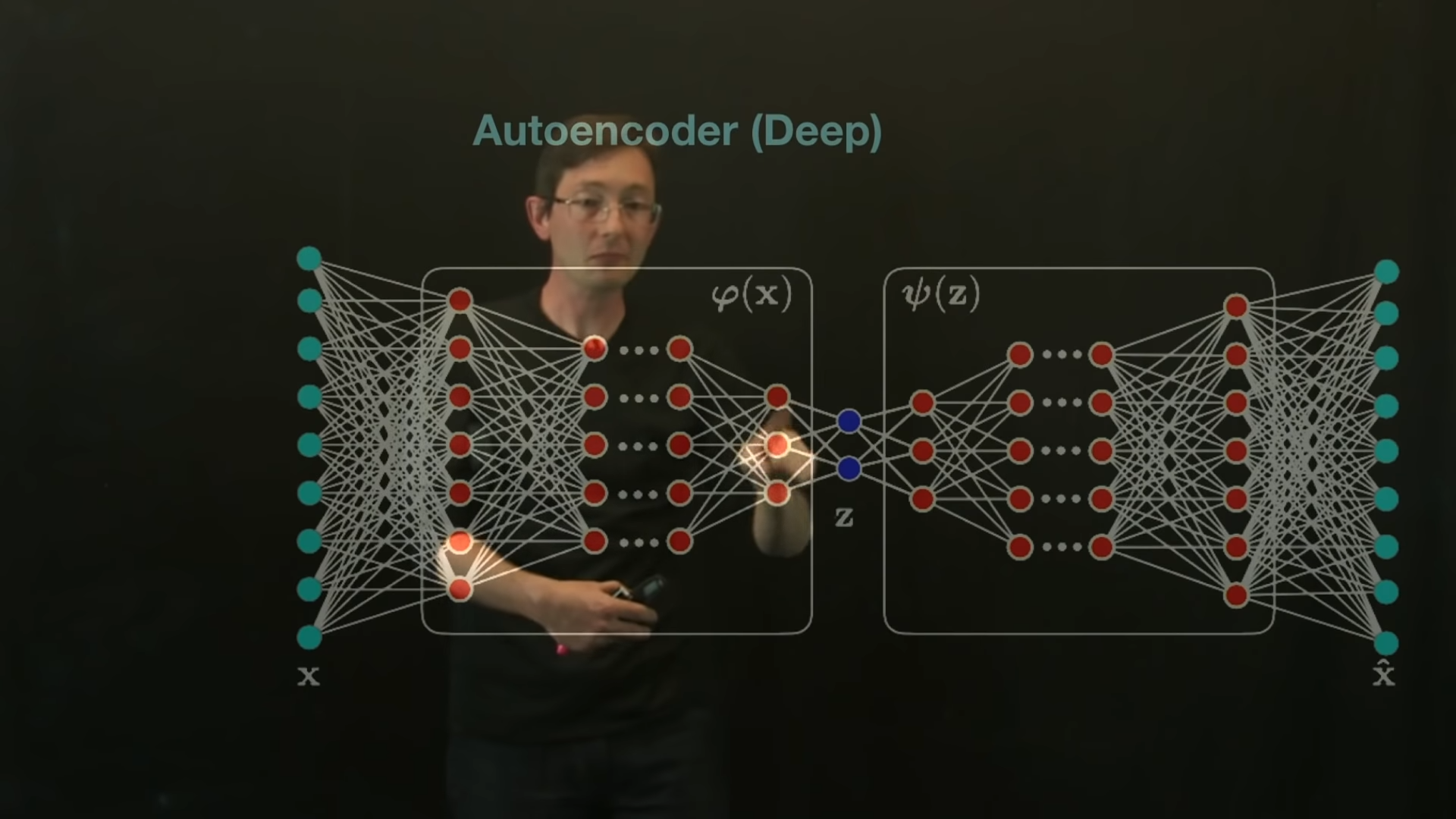
Types of ML

HPC + AI
HPC + Ai: Machine Learning Models in Scientific Computing
This YouTube video and see the slide here.
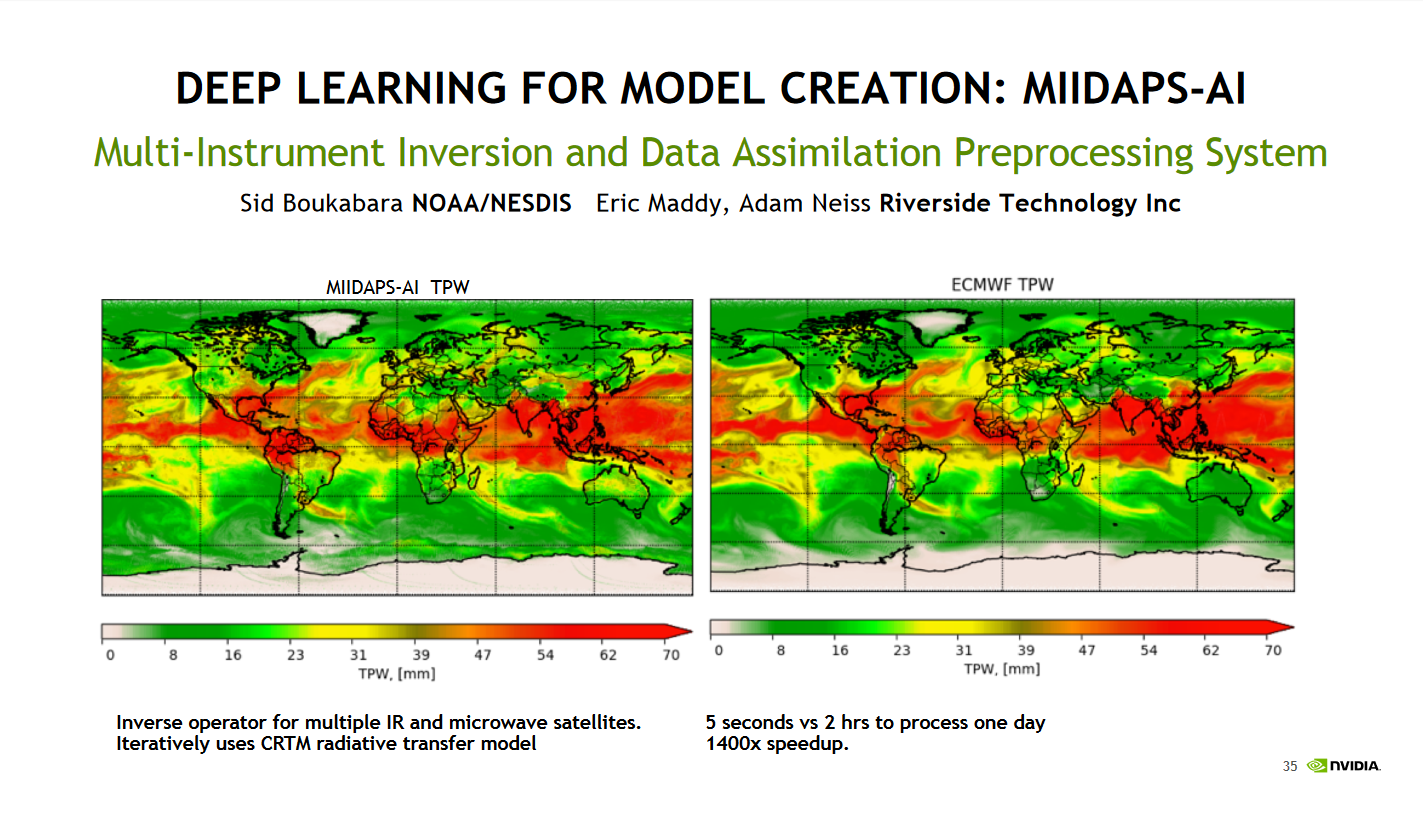

How machine learning can improve HPC applications
Traditionally, the main workloads run on a supercomputer consists of various forms of numerical simulations, such as weather modelling, molecular dynamics, etc.
Early results indicate that these models, that combine machine learning and traditional simulation, can improve accuracy, accelerate time to solution and significantly reduce costs.
And in that context, is it a pre- or post-processing step to help filter and understand the input data or ultimate simulation results, or is it something that is poised to (partly) replace the decades-old codes that comprise many HPC workloads?
Consequently, early research projects have shown that machine learning often requires orders of magnitude fewer resources to unlock problems that have often been beyond the grasp of traditional techniques. Since performance increases in traditional high-performance computing (HPC) have been highly dependent on Moore’s Law, this approach presents a promising avenue to explore.
Use of machine learning to increase the resolution of a traditional numerical simulation. The traditional simulation would still be used for simulation at the conventional grid size, while the machine learning model could use that as input to make predictions at an increased resolution.

Supercomputers and Machine Learning: A Perfect Match - insideBIGDATA
Unlike traditional computers, supercomputers use parallel processing. This multitasking capability enables supercomputers to process calculations at a much faster rate.
What Is High-Performance Computing and How Does it Work?
HPC architectures typically consist of three components: the Compute Cluster, the Network and Data Storage.
To Cloud or Not to Cloud?
Big data is too big to be processed using traditional database techniques. The cloud provides the scalability and flexibility required to process such large data sets. Hardware virtualization, for example, enables organizations to scale easily. This is useful for data-intensive applications.
However, there are some considerations when moving big data operations to the cloud. Such large and varied amounts of data can be problematic to synch between on-premises data centers and the cloud. This can affect the I/O performance in the cloud environment.
Scientists are using machine learning techniques to improve the auto-tuning of exascale applications.
High-performance computing provides unique advantages for machine learning models, including:
- Large amounts of floating-point operations (FLOPS)
- Low-latency
- Parallel I/O