[Read Paper] FPGA/DNN Co-Design: An Efficient Design Methodology for IoT Intelligence on the Edge
FPGA/DNN Co-Design: An Efficient Design Methodology for IoT Intelligence on the Edge
Develop DNNs and the corresponding FPGA accelerators simultaneously. DNN designs should be FPGA-architecture driven, and FPGA accelerators should be DNN-aware.
Contributions
- simultaneous FPGA/DNN co-design methodology with
- hardware-oriented DNN model design following bottom-up approach;
- DNN-driven FPGA accelerator design following top-down approach.
- For DNN model design, we introduce a DNN template to guide the DNN generation with predictable performance and resource utilization, which greatly reduces the co-design search space. Based on such template, an automatic DNN model search engine,
Auto-DNN, is proposed to effectively explore the design space and generate DNN models for desired QoR. - For FPGA accelerator design, we introduce a fine-grained tile-based pipeline architecture, which supports arbitrary DNNs generated by
Auto-DNNusing a library of highly optimized HLS IPs. Based on such architecture, an automatic HLS generator,Auto-HLS, is proposed to directly generate synthesizable C code of the DNN models, to conduct latency/resource estimation and FPGA accelerator generation. - We demonstrate our co-design approach on an object detection task targeting a PYNQ-Z1 embedded FPGA. DNN models are searched and mapped to the board with the state-of-the-art performance regarding accuracy, speed, and power efficiency.
Some Knowledge About DNN
- DNN design is conducted either manually by machine learning experts or automatically by Neural Architecture Search (NAS) such as recursive neural networks (RNN) and reinforcement learning.
- quantization and model compression are used to reduce DNN model size
- latency-directed resource allocation and fine-grained pipeline architecture are proposed to deliver low latency during DNN inference
FPGA/DNN Co-Design
Design Space
- DNN design
- the number and types of layers
- the number of input/output channels
- residual connections
- concatenations
- FPGA accelerator
- IP instance categories
- IP reuse strategies
- quantization schemes
- parallel factors
- data transfer behaviors
- buffer sizes
For FPGA accelerator, use IP-based design strategy. Each IP supports a basic DNN layer type (e.g. Conv, Pooling), which must be instantiated and configured if the DNN model contains such type of layer.

Co-Design Flow
-
Co-Design Step 1: Building block and DNN modeling. Capture the hardware latency and resource utilization of DNN building blocks and hardware IP pool.
- Co-Design Step 2: Building block selection.
Auto-DNNperforms both coarse and fine-grained evaluations of the building blocks regarding three most important features: latency, resource utilization and accuracy.- Based on the evaluation, building blocks on the Pareto curve will be selected for further DNN exploration.
- Co-Design Step 3: Hardware-aware DNN search and update.
- Given selected building blocks,
Auto-DNNexplores the DNNs under given resource and latency constraints by using stochastic coordinate descent (SCD). - DNNs output from SCD are passed to
Auto-HLSto get more precise performance and resource results - Are fed back to SCD for update.
- The generated DNNs that meet performance and resource requirements are output for training and fine-tuning.
- Given selected building blocks,
Four Components
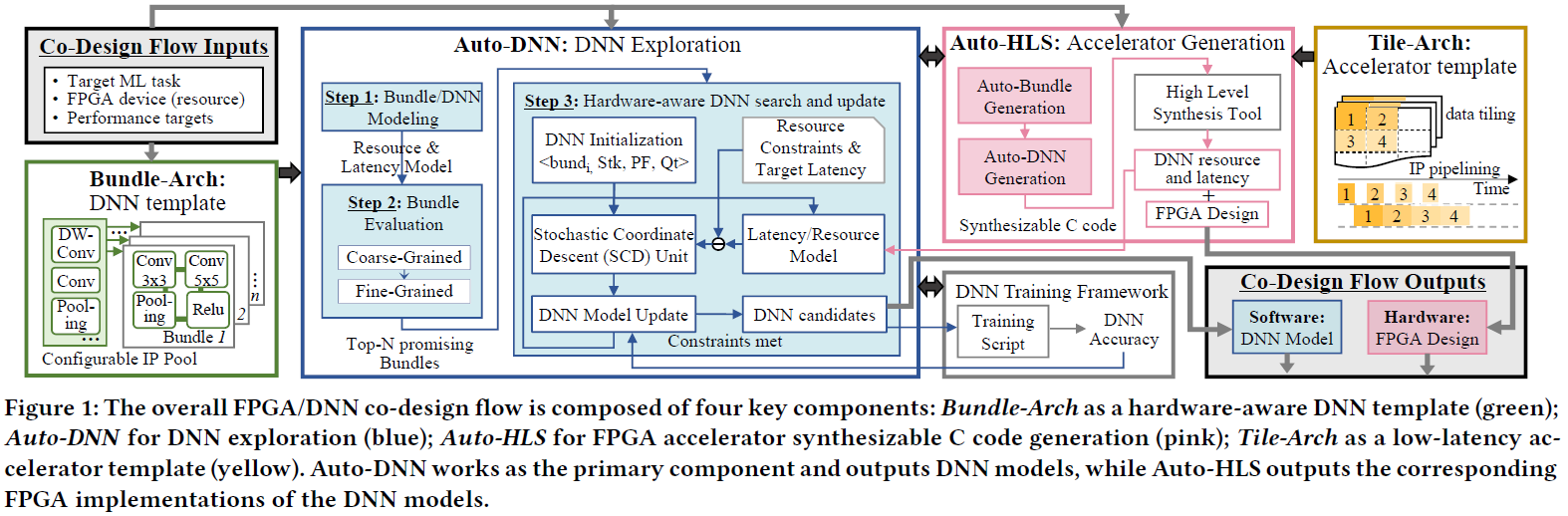
Bundle-Archas a hardware-aware DNN template (green)Tile-Archas a low-latency accelerator template (yellow)Auto-DNNfor DNN exploration (blue), works as the primary component and outputs DNN modelsAuto-HLSfor FPGA accelerator synthesizable C code generation (pink), outputs the corresponding FPGA implementations of the DNN models