[Weekly Review] 2020/05/25-31
Published:
by
SingularityKChen
![]() (Last updated:
)
(Last updated:
)
- Categories:
- WeeklyReview 81
- Tags:
- ML 3
- PowerWall 1
- Software2 1
2020/05/25-31
This week, I attended two online meeting grouped by TinyML.
Webinar for Young Excellence - The Intersection of SSCS and AI – A Tale of Two Journeys - Vivienne Sze & Boris Murmann
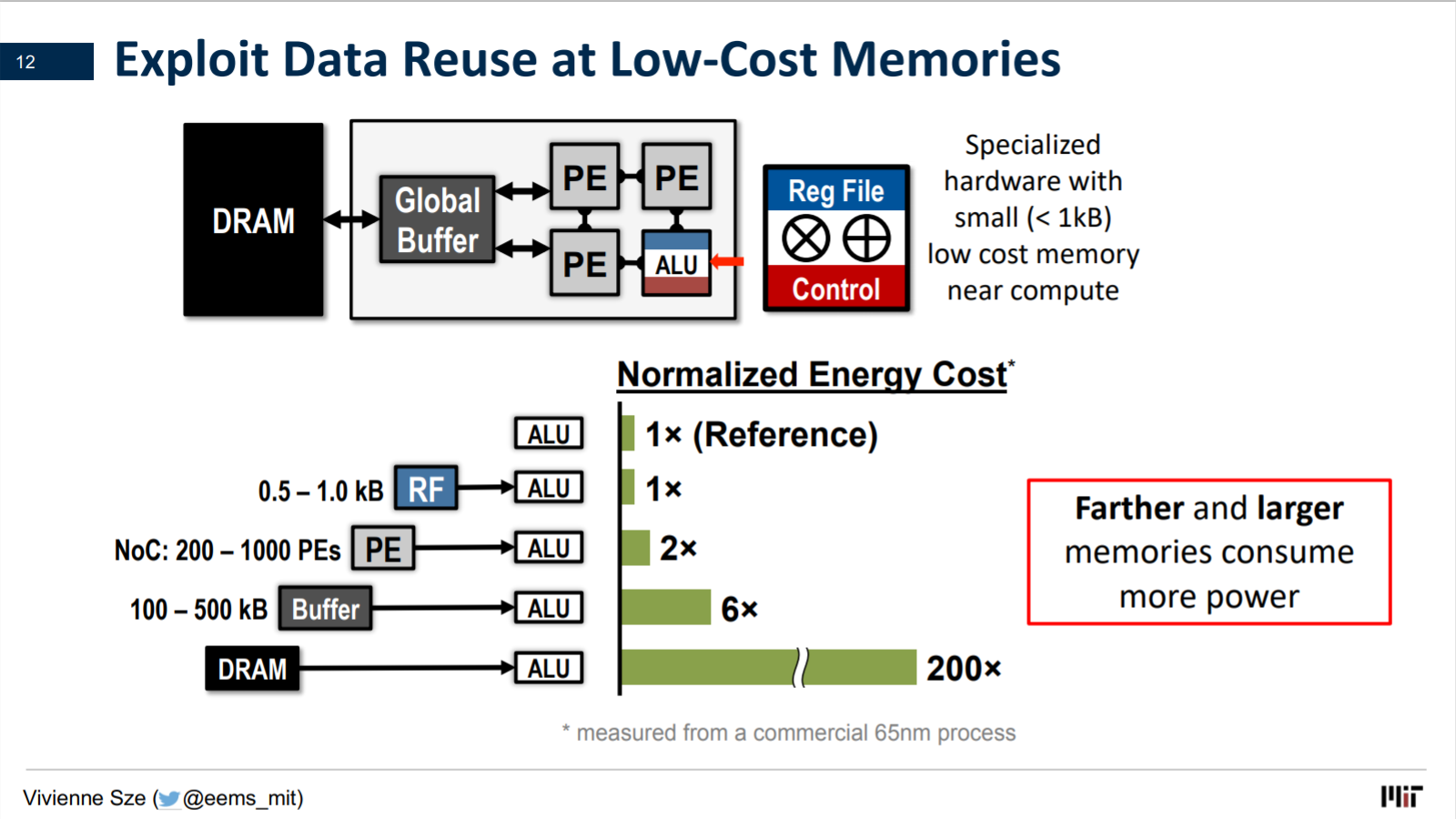

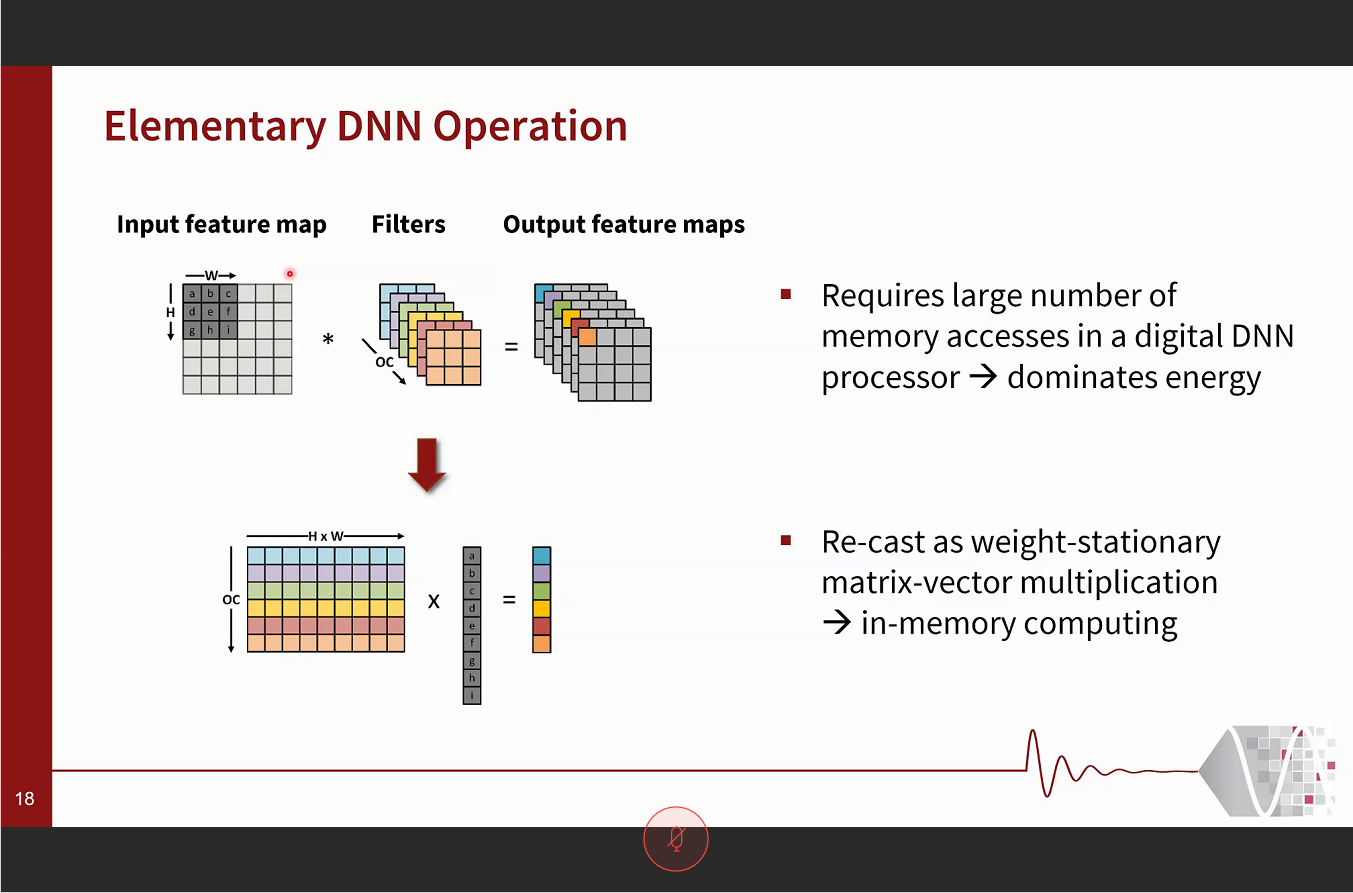
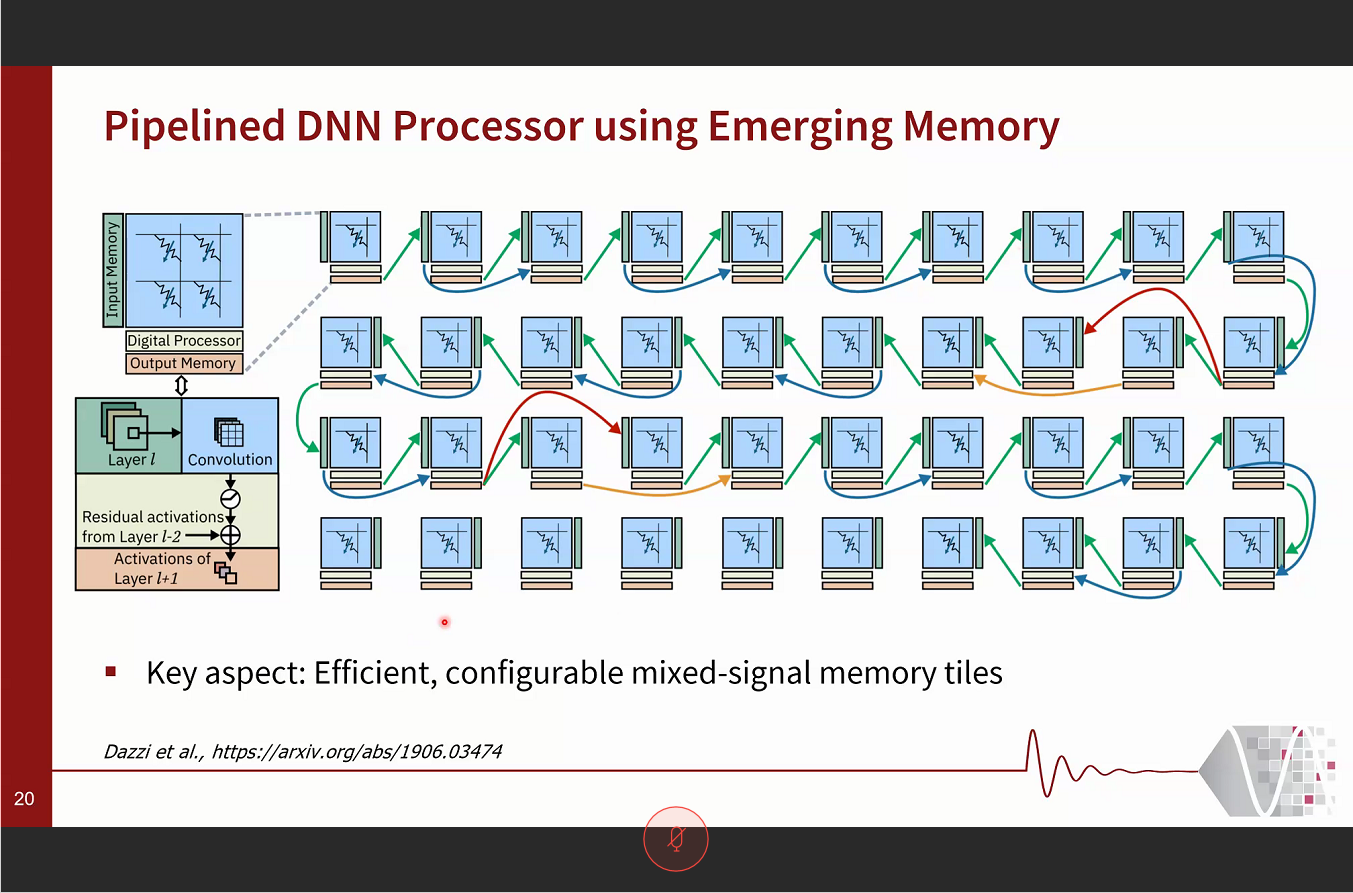

Pulse-latch approach reduces dynamic power
These methodologies, however, impose restrictive physical constraints which have schedule impact or which are heavily dependent on logic functions such as clock gating.
Introduction
Dynamic power is consumed across all elements of a chip. The clock network is one of the large consumers of dynamic power. According to a recent IBM study [1], half of dynamic power is dissipated in the clock network.
Flip-flop synchronization with the clock edge is widely used because it is matched with static timing analysis (STA). Timing optimization based on STA is must for SoCs. On the other hand, designers may choose to use a latch for storing the state. A latch is simple and consumes much less power than that of the flip-flop. However, it is difficult to apply static timing analysis with latch design because of the data transparent behavior.
Pulsed latch concept
A latch can capture data during the sensitive time determined by the width of clock waveform. If the pulse clock waveform triggers a latch, the latch is synchronized with the clock similarly to edge-triggered flip-flop because the rising and falling edges of the pulse clock are almost identical in terms of timing.

Designing Computer Systems for Software 2.0

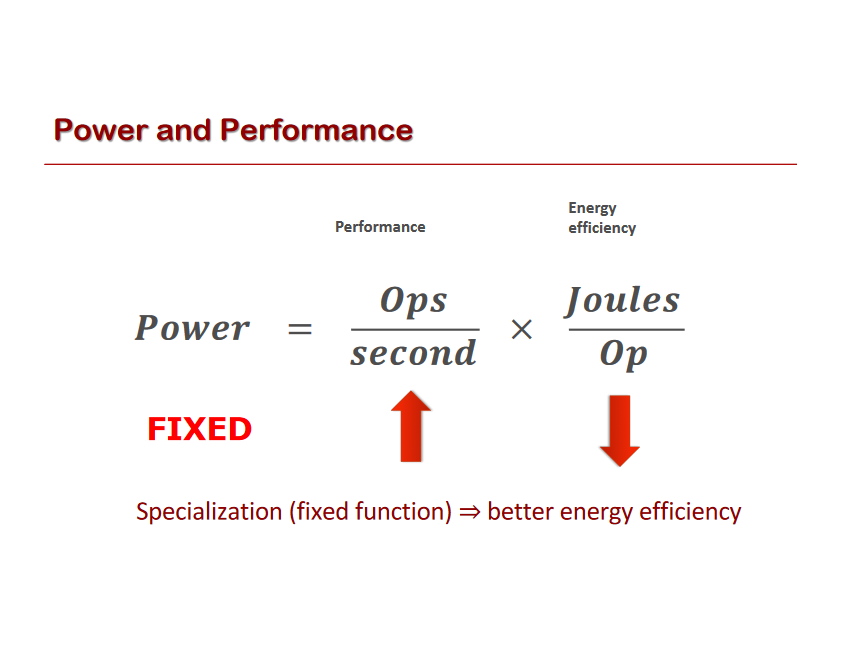
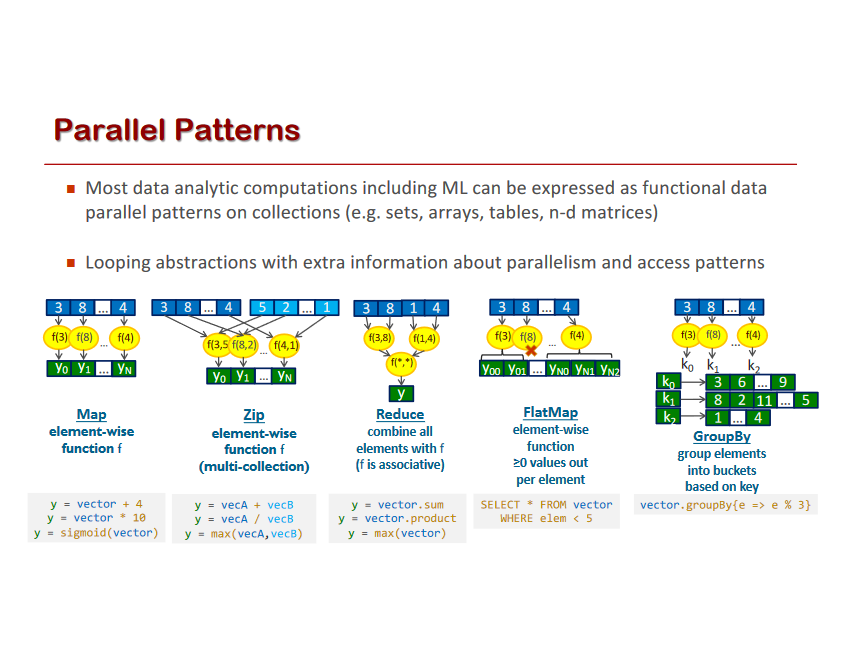

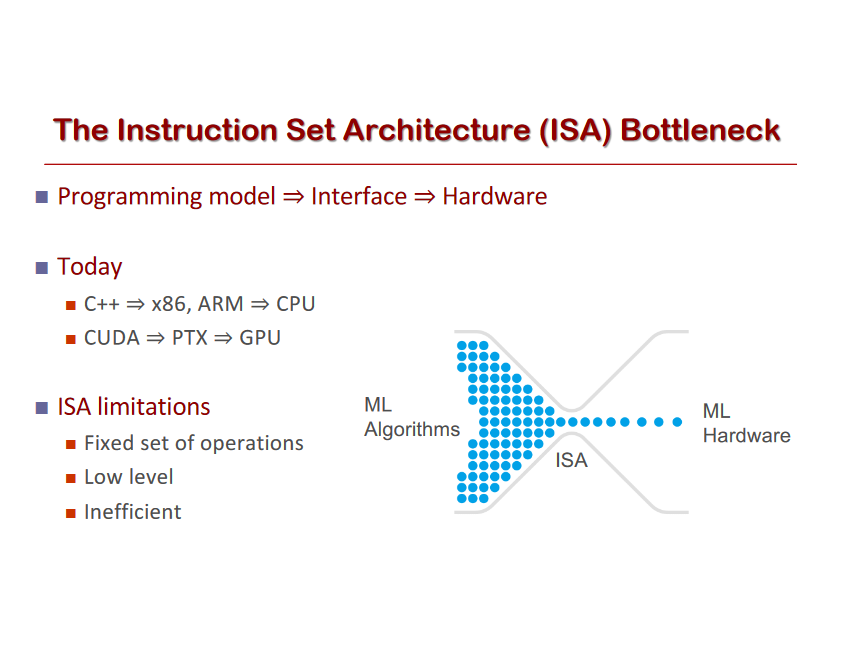
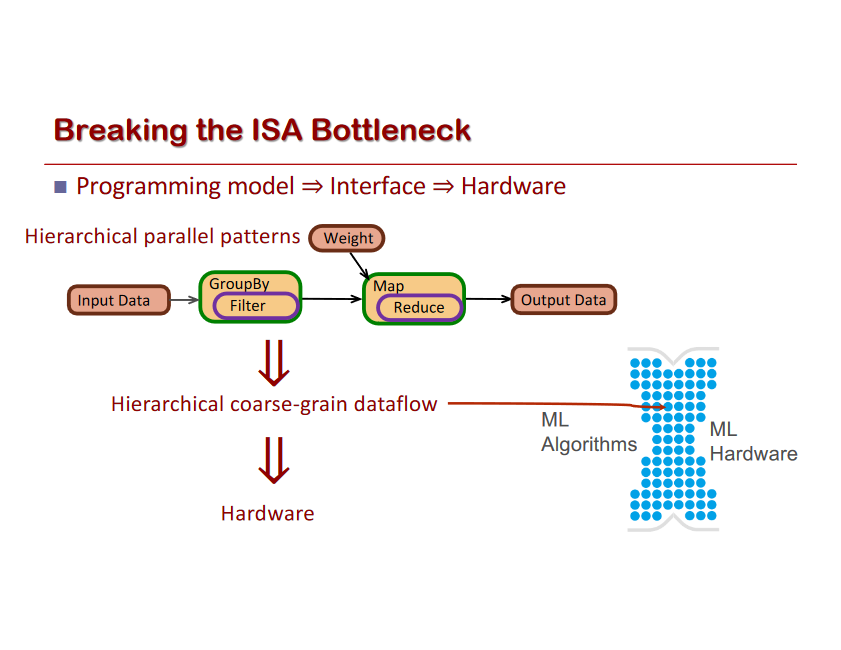
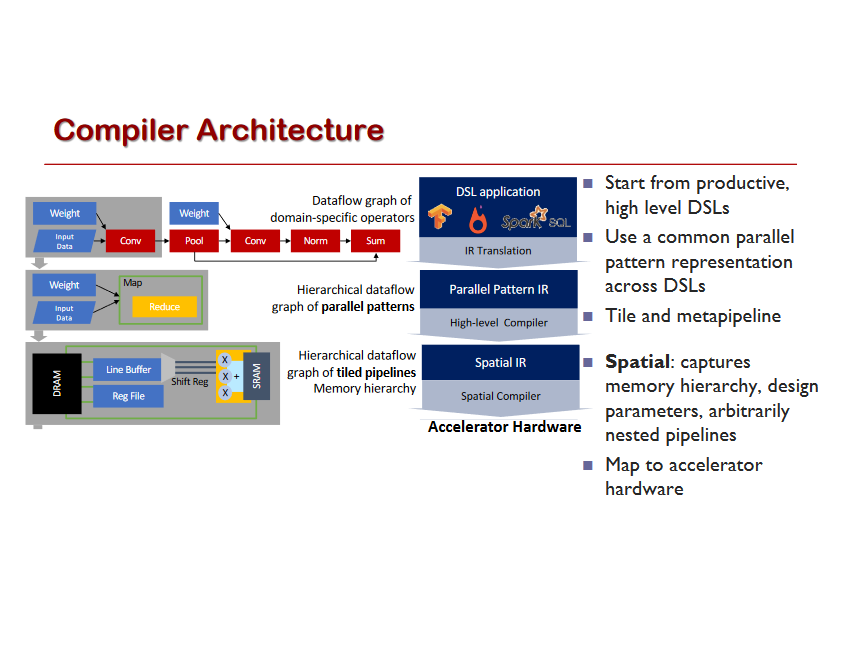

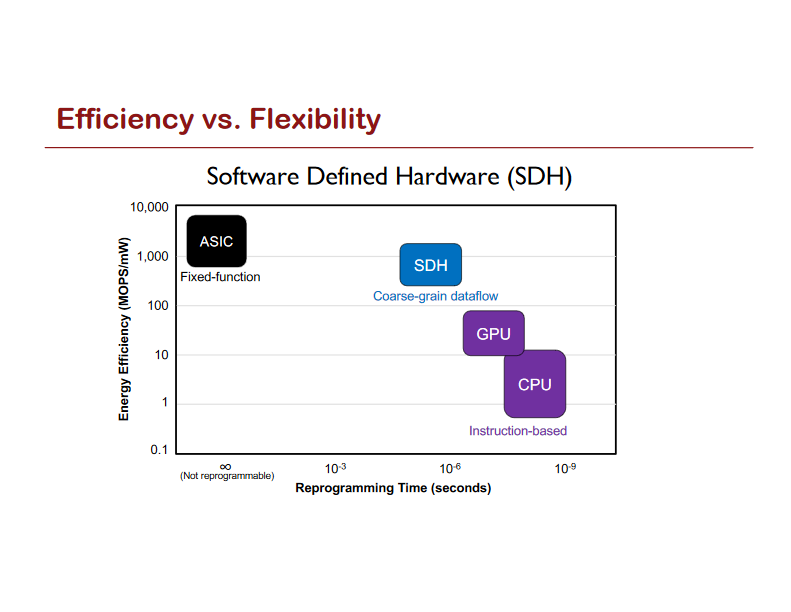
Let’s take a look at some of the benefits of Software 2.0 (think: a ConvNet) compared to Software 1.0 (think: a production-level C++ code base). Software 2.0 is:
Computationally homogeneous. A typical neural network is, to the first order, made up of a sandwich of only two operations: matrix multiplication and thresholding at zero (ReLU). Compare that with the instruction set of classical software, which is significantly more heterogenous and complex. Because you only have to provide Software 1.0 implementation for a small number of the core computational primitives (e.g. matrix multiply), it is much easier to make various correctness/performance guarantees.
Simple to bake into silicon. As a corollary, since the instruction set of a neural network is relatively small, it is significantly easier to implement these networks much closer to silicon, e.g. with custom ASICs, neuromorphic chips, and so on. The world will change when low-powered intelligence becomes pervasive around us. E.g., small, inexpensive chips could come with a pretrained ConvNet, a speech recognizer, and a WaveNet speech synthesis network all integrated in a small protobrain that you can attach to stuff.
Constant running time. Every iteration of a typical neural net forward pass takes exactly the same amount of FLOPS. There is zero variability based on the different execution paths your code could take through some sprawling C++ code base. Of course, you could have dynamic compute graphs but the execution flow is normally still significantly constrained. This way we are also almost guaranteed to never find ourselves in unintended infinite loops.
Constant memory use. Related to the above, there is no dynamically allocated memory anywhere so there is also little possibility of swapping to disk, or memory leaks that you have to hunt down in your code.
It is highly portable. A sequence of matrix multiplies is significantly easier to run on arbitrary computational configurations compared to classical binaries or scripts.
It is very agile. If you had a C++ code and someone wanted you to make it twice as fast (at cost of performance if needed), it would be highly non-trivial to tune the system for the new spec. However, in Software 2.0 we can take our network, remove half of the channels, retrain, and there — it runs exactly at twice the speed and works a bit worse. It’s magic. Conversely, if you happen to get more data/compute, you can immediately make your program work better just by adding more channels and retraining.
Modules can meld into an optimal whole. Our software is often decomposed into modules that communicate through public functions, APIs, or endpoints. However, if two Software 2.0 modules that were originally trained separately interact, we can easily backpropagate through the whole. Think about how amazing it could be if your web browser could automatically re-design the low-level system instructions 10 stacks down to achieve a higher efficiency in loading web pages. With 2.0, this is the default behavior.
It is better than you. Finally, and most importantly, a neural network is a better piece of code than anything you or I can come up with in a large fraction of valuable verticals, which currently at the very least involve anything to do with images/video and sound/speech.