[Read Paper] Very Long Instruction Word Architectures and the ELI-512
Very Long Instruction Word Architectures and the ELI-512
Superscalar CPUs use hardware to decide which operations can run in parallel at runtime, while VLIW CPUs use software (the compiler) to decide which operations can run in parallel in advance. Because the complexity of instruction scheduling is moved into the compiler, complexity of hardware can be reduced substantially.
Three problems to be solved
These problems include
- highly parallel code generation,
- multiple tests in each cycle,
- multiple memory references in each cycle.
The properties of VLIW
- There is one central control unit issuing a single long instruction per cycle.
- Each long instruction consists of many tightly coupled independent operations.
- Each operation requires a small, statically predictable number of cycles to execute.
- Operations can be pipelined.
These properties distinguish VLlWs from multiprocessors (with large asynchronous tasks) and dataflow machines (without a single flow of control, and without the tight coupling).
VLIWs vs. Vector Machines
VLIWs put fine-grained, tightly coupled, but logically unrelated operations in single instructions. Vector machine do many fine-grained, tightly coupled, logically related operations at once the elements of a vector.
Vector machines can do many parallel operations between tests; VUWs cannot.
Vector machines can structure memory inferences to entire arrays or slices of arrays; VLIWs cannot.
Trace scheduling
Experiments showed that the parallelism within basic blocks is very limited. But a radically new global compaction technique called trace scheduling can find large degrees of parallelism beyond basic-block boundaries.
Horizontal microcode is like VLIW architectures in its style of parallelism.
VLlWs have much more parallelism than horizontal microcode, and these techniques require too expensive a search to exploit it.
Trace scheduling replaces block-by-block compaction of code with the compaction of long streams of code, possibly thousands of instructions long.
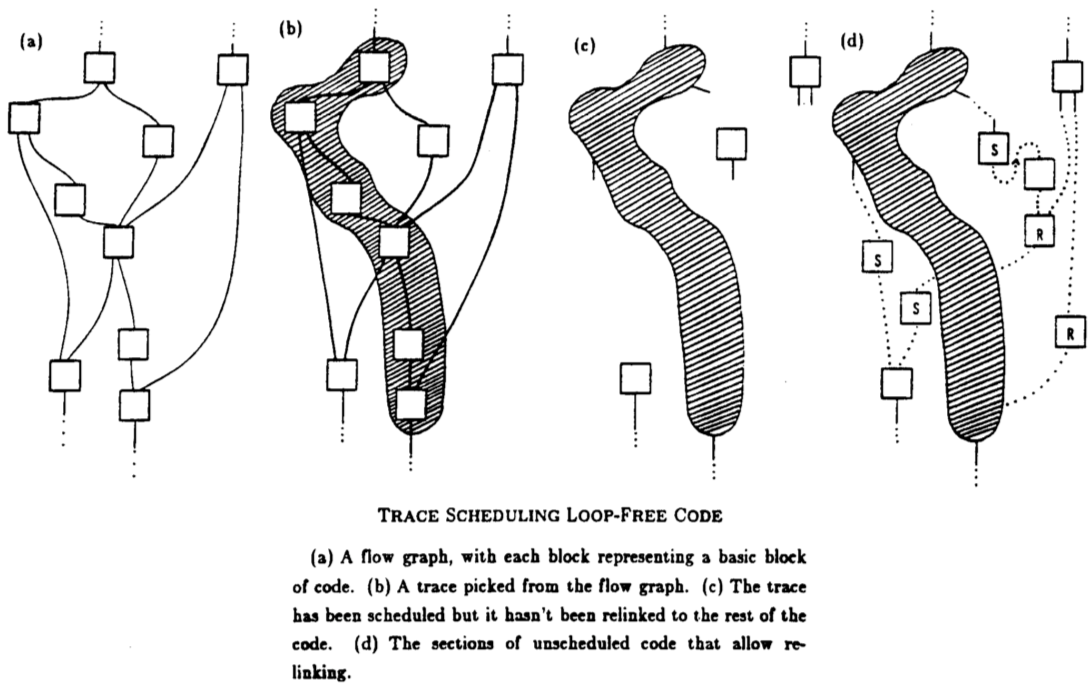
Dynamic information - jump predictions - is used at compile time to select streams with the highest probability of execution. Those streams we call “traces.” We pick our first trace from the most frequently executed code.
After scheduling is complete, the scheduler has made many code motions that will not correctly preserve jumps from the stream to the outside world (or rejoins back). So a postprocessor inserts new code at the stream exits and entrances to recover the correct machine state outside the stream.
Then we look for our second trace.
Memory anti-aliasing on bulldog
Code motions are restricted by data precedence. \(\begin{eqnarray*} Z := A + X \tag{1} \\ A := Y + W \tag{2} \end{eqnarray*}\) Our code motions must not cause $(2)$ to be scheduled earlier than $(1)$. So the trace scheduler builds a data-precedence edge before scheduling. \(\begin{eqnarray*} Z := A[expr1] + X \tag{1} \\ A[expr2] := Y + W \tag{2} \end{eqnarray*}\) Whether $(2)$ may be done earlier than $(1)$ is ambiguous.
Answering this question is the problem of anti-aliasing memory references.
when indirect references are to array elements, we can usually tell they are different at compile time.
VLIWs need clever jump mechanisms
If we are going to pack a great many operations into each cycle, we had better be prepared to make more than one test per cycle.
Clearly we need a mechanism for jumping to one of several places indicated by the results of several tests.
The most convenient support the architecture could possibly provide would be a $2^n$-way jump based on the results of testing $n$ independent conditions.
After we had actually implemented trace scheduling, a surprising fact emerged: What trace scheduling requires is a mechanism for jumping to any of $n+1$ locations as the result of $n$ independent tests.
VLIW compilers must predict memory banks
With so many operations packed in each cycle, many of them will have to be memory references.
But (m in any parallel processing system) we cannot simply issue many references each cycle; two things will go wrong.
- Getting the addresses through some kind of global arbitration system will take a long time.
- And the probability of bank conflict will approach 1, requiring us to freeze the entire machine most cycles.
For unpredictable reference:
- First of all, we might simply have no chance to predict the bank address of a refence. Our solution is ta build a shadow memory-access system that takes addresses for any bank whatsoever and returns the values at those addresses
- The second problem is that even when we have arrays and have unrolled the loops properly, we might not be able to predict the bank location of a subscript. Unknown starting values don’t ruin our chances of doing predictable references inside the loop. All we have to do is ask the compiler to set up a kind of pre-loop.
Conclusion
Our code generators use
- trace scheduling for locating and specifying parallelism originating in far removed places in the code.
- The $n+1$-way jump mechanism makes it possible to schedule enough tests in each cycle without making the machine too big.
- Bank prediction, precedence for local searches, and pre-looping make it possible to schedule enough memory references in each cycle without making the machine too slow.
Pros and Cons of VLIW1
Pros
- reduce the complexity of hardware, accelerating the design and implementations of chips, leaving the complexity to the software;
- the highly parallelly excurse will not suffer the performance or fluency. It can also hold the linear relationship between the issue width and performance.
- the compiler can optimize the whole instructions on a high level, compared to hardware, which can only reschedule the instructions within one or two hundreds instructions.
Cons
- many data is available only in run-time, especially some controller message, hence reducing the efficiency dramatically.
- lack the backward compatibility.
VLIW succeeds in DSP area as it's algorithm is stable and computing-bound. It need a fix-cycle TCM instead of the Cache.
-
VLIW的前世今生:为什么DL加速器都青睐于它, https://zhuanlan.zhihu.com/p/101538383 ↩