[Read Paper] In-Datacenter Performance Analysis of a Tensor Processing Unit
Published:
by
SingularityKChen
![]() (Last updated:
)
(Last updated:
)
- Categories:
- ReadPaper 30
- Tags:
- DLA 19
- DNN 12
- Inference 1
- TPU 5
In-Datacenter Performance Analysis of a Tensor Processing Unit
The heart of the TPU is a 65,536 8-bit MAC matrix multiply unit that offers a peak throughput of 92 TeraOps/second (TOPS) and a large (28 MiB) software-managed on-chip memory.
TPU ORIGIN, ARCHITECTURE, IMPLEMENTATION, AND SOFTWARE
Goal
- The goal was to improve cost-performance by 10X over GPUs.
- The goal was to run whole inference models in the TPU to reduce interactions with the host CPU and to be flexible enough to match the NN needs of 2015 and beyond
Architecture
- Rather than be tightly integrated with a CPU, to reduce the chances of delaying deployment, the TPU was designed to be a coprocessor on the PCIe I/O bus, allowing it to plug into existing servers just as a GPU does.
- Moreover, to simplify hardware design and debugging, the host server sends TPU instructions for it to execute rather than the TPU fetching them itself.
- Hence, the TPU is closer in spirit to an FPU (floating-point unit) coprocessor than it is to a GPU.
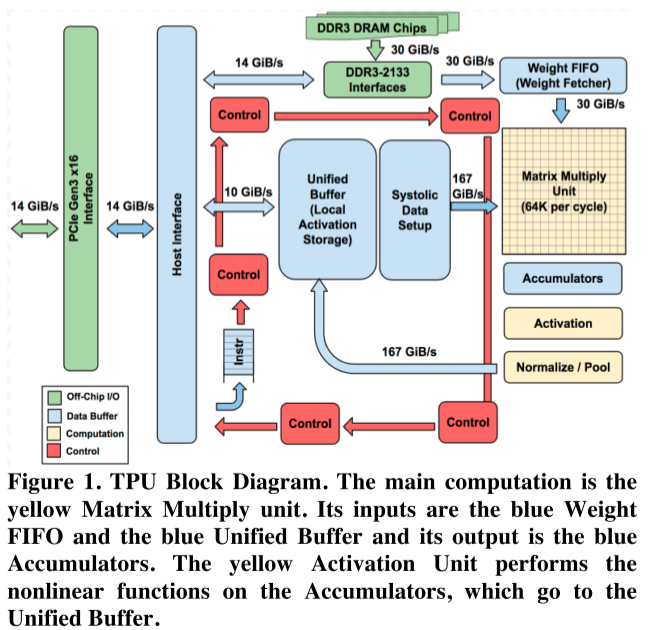
Implementation
- The TPU instructions are sent from the host over the PCIe Gen3 x16 bus into an instruction buffer. TPU instructions follow the CISC tradition, including a repeat field. The average clock cycles per instruction (CPI) of these CISC instructions is typically 10 to 20.
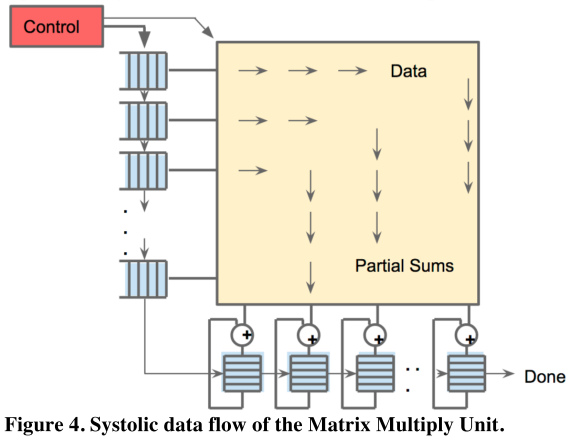
- the Matrix Multiply Unit is the heart of the TPU. It contains 256x256 MACs that can perform 8-bit multiply-and-adds on signed or unsigned integers. It reads and writes 256 values per clock cycle and can perform either a matrix multiply or a convolution.
- The philosophy of the TPU microarchitecture is to keep the matrix unit busy. It uses a 4-stage pipeline for these CISC instructions, where each instruction executes in a separate stage.
- As reading a large SRAM uses much more power than arithmetic, the matrix unit uses systolic execution to save energy by reducing reads and writes of the Unified Buffer.
Software
Like GPUs, the TPU stack is split into a User Space Driver and a Kernel Driver. The Kernel Driver is lightweight and handles only memory management and interrupts. It is designed for long-term stability.
The User Space driver sets up and controls TPU execution, reformats data into TPU order, translates API calls into TPU instructions, and turns them into an application binary.
The TPU runs most models completely from inputs to outputs, maximizing the ratio of TPU compute time to I/O time.
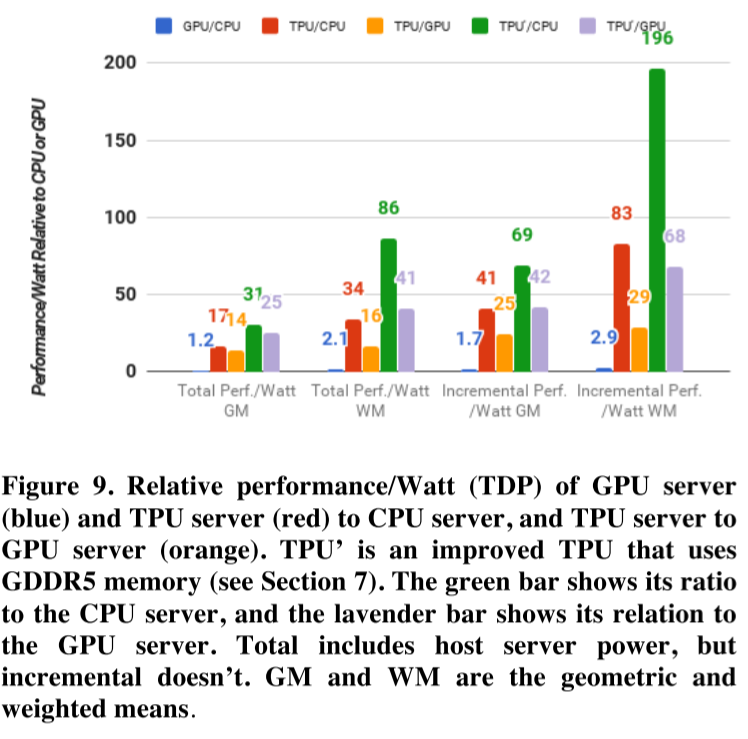
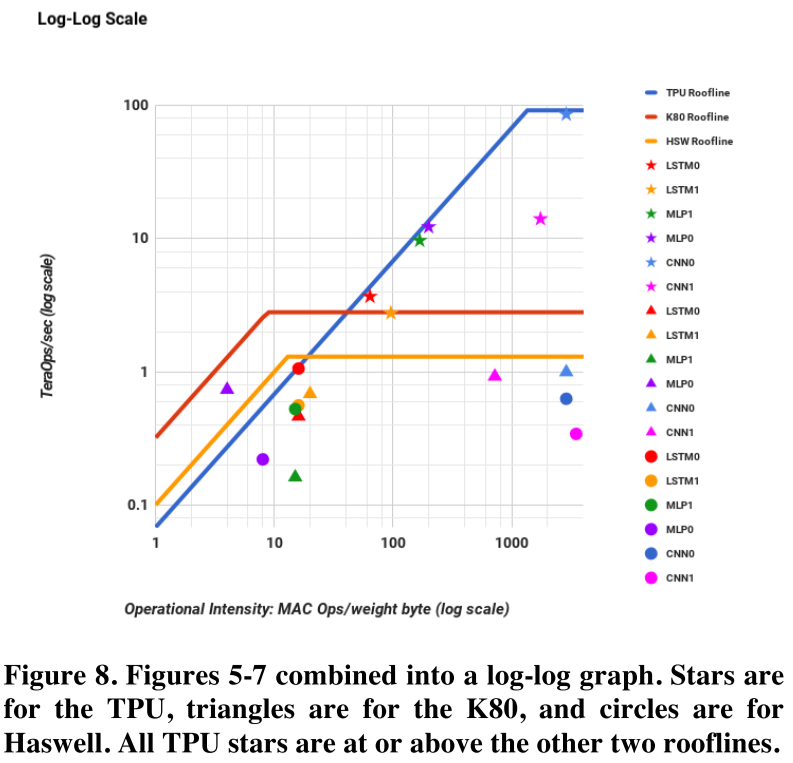
Performance