[Glean] Tomasulo Algorithm
Published:
by
SingularityKChen
![]() (Last updated:
)
(Last updated:
)
- Categories:
- Glean 53
- Tomasulo Algorithm
Tomasulo Algorithm
Problem to solve1
There were just four floating point registers, which prevented interesting compiler shceduleing of operations, as it might need more registers.
This algorithm aimed to increase the effective number of registers, i.e., renaming in hardware.
Three hazards it can solve
Data dependence hazard: Read After Write hazard
It's a hazard caused by True Dependence, where instruction J is data dependent on instruction I.1
I: add r1, r2, r3
J: sub r4, r1, r3
RAW hazards eliminated by forwarding2
- source operand values that are computed after the registers are read are known by the functional unit or load buffer that will produce them
- results are immediately forwarded to functional units on the common data bus
- don’t have to wait until for value to be written into the register file
Name dependence hazard: Write After Read hazard
Name dependence: when two instructions use same register or memory location, called a name, but no flow of data between the instructions associated with that name.
This WAR hazard is also called anti-dependence hazard, where instruction J writes operand before instruction I reads it.1
I: sub r4, r1, r3
J: add r1, r2, r3
K: mul r6, r1, r7
Eliminate WAR hazards by register renaming:2
-
name-dependent instructions refer to reservation station or load buffer locations for their sources, not the registers (as above) at issue time
-
the last writer to the register updates it
-
more reservation stations than registers, so eliminates more name dependences than a compiler can & exploits more parallelism
Tag in the reservation station/register file/store buffer indicates where the result will come from.
Name dependence hazard: Write After Write hazard
This WAW hazard is also called output dependence, where instruction J writes operand before instruction I write it.2
I: sub r1,r4,r3
J: add r1,r2,r3
K: mul r6,r1,r7
It can be also eliminated by Tomasulo Algorithm using register renaming.2
Hardware for Tomasulo Algorithm
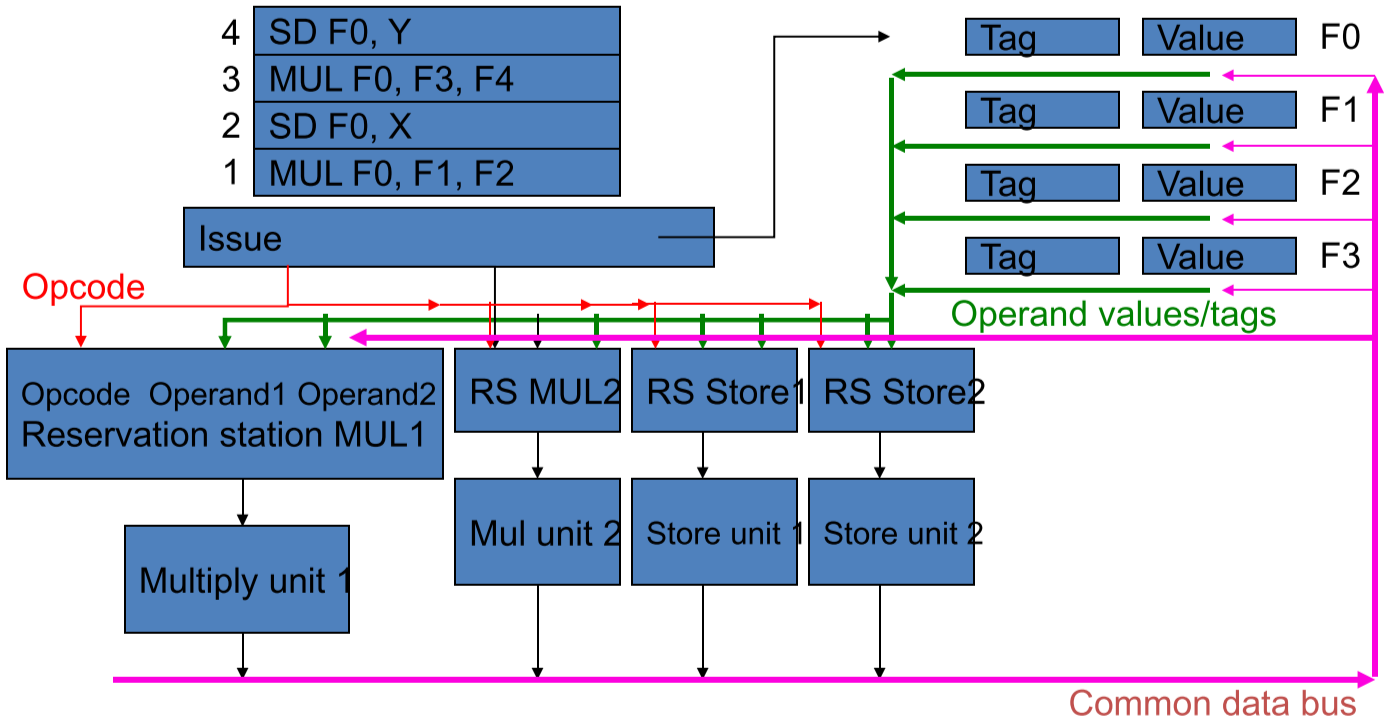
- Instruction fetch queue
- Float Point Registers: contains either values or tags. The tag means where the results of this register will come from. If the tag is null, then the value is valid.
- Common Data Bus: used to broadcast the computing results and tags from the computing unit.
Three stages of Tomasulo Algorithm1
Issue—get instruction from FP Op Queue
If reservation station free (no structural hazard), control issues instr & sends operands (renames registers).
- Each instruction is issued in order
- Issue unit collects operands from the two instruction’s source registers
- Result may be a value, or, if value will be computed by an uncompleted instruction, the tag of the RS to which it was issued
- put tag of producing functional unit (RS) or load buffer to FP Reg2
- When instruction 1 is issued, F0 is updated to get result from MUL1
- When instruction 3 is issued, F0 is updated to get result from MUL2
Execute—operate on operands (EX) When both operands ready then execute
- RAW hazard detection
- snoop on common data bus for missing operands
- dispatch instruction to a functional unit when obtain both operand values
- execute the operation
- calculate effective address & start memory operation
Write result—finish execution (WB) Write on Common Data Bus to all awaiting units
- Instructions may complete out of order
- Result is broadcast on CDB
- Carrying tag of RS to which instruction was originally issued
- All RSs and registers monitor CDB and collect value if tag matches
- Any RS which has both operands and whose FU is free fires.
- When MUL1 completes result goes to store unit but not F0
Tomasulo Drawbacks
- Complexity
- Many associative stores (CDB) at high speed
- performance limited by common data bus
- Each CDB must go to multiple functional units, leads to high capacitance, high wiring density
- Number of functional units that can complete per cycle limited to one
- Non-precise interrupts
- In-order issue, out-of-order execution, and out-of-order completion
- able to solve it by adding an extra commit stage and reordered buffer as well as commit side buffer.
-
Dynamic scheduling, out-of-order execution, register renaming and speculative execution, https://www.doc.ic.ac.uk/~phjk/AdvancedCompArchitecture/Lectures/pdfs/Ch03-AdvCompArch-DynamicScheduling-PaulKelly-V04.pdf ↩ ↩2 ↩3 ↩4
-
https://courses.cs.washington.edu/courses/csep548/06au/lectures/tomasulo.pdf ↩ ↩2 ↩3 ↩4 ↩5