[Glean] CUDA Programming Model
Published:
by
SingularityKChen
![]() (Last updated:
)
(Last updated:
)
- Categories:
- Glean 53
CUDA Programming Model1
Kernels
CUDA C++ extends C++ by allowing the programmer to define C++ functions, called kernels, that, when called, are executed N times in parallel by N different CUDA threads, as opposed to only once like regular C++ functions.
A kernel is defined using the __global__ declaration specifier and the number of CUDA threads that execute that kernel for a given kernel call is specified using a new <<<...>>> execution configuration syntax.
Each thread that executes the kernel is given a unique thread ID that is accessible within the kernel through built-in variables.
// Kernel definition
__global__ void VecAdd(float* A, float* B, float* C)
{
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main()
{
...
// Kernel invocation with N threads
VecAdd<<<1, N>>>(A, B, C);
...
}
Thread Hierarchy
For convenience, threadIdx is a 3-component vector, so that threads can be identified using a one-dimensional, two-dimensional, or three-dimensional thread index, forming a one-dimensional, two-dimensional, or three-dimensional block of threads, called a thread block.
This provides a natural way to invoke computation across the elements in a domain such as a vector, matrix, or volume.
The index of a thread and its thread ID relate to each other in a straightforward way:
- For a one-dimensional block, they are the same;
- For a two-dimensional block of size
(Dx, Dy), the thread ID of a thread of index(x, y)is(x + y Dx); - For a three-dimensional block of size
(Dx, Dy, Dz), the thread ID of a thread of index(x, y, z)is(x + y Dx + z Dx Dy).
Thread Blocks
There is a limit to the number of threads per block, since all threads of a block are expected to reside on the same streaming multiprocessor core and must share the limited memory resources of that core. On current GPUs, a thread block may contain up to 1024 threads.
However, a kernel can be executed by multiple equally-shaped thread blocks, so that the total number of threads is equal to the number of threads per block times the number of blocks.
Blocks are organized into a one-dimensional, two-dimensional, or three-dimensional grid of thread blocks. The number of thread blocks in a grid is usually dictated by the size of the data being processed, which typically exceeds the number of processors in the system.
Thread blocks are required to execute independently: It must be possible to execute them in any order, in parallel or in series. This independence requirement allows thread blocks to be scheduled in any order across any number of cores
Threads within a block can cooperate by sharing data through some shared memory and by synchronizing their execution to coordinate memory accesses.
More precisely, one can specify synchronization points in the kernel by calling the __syncthreads() intrinsic function; __syncthreads() acts as a barrier at which all threads in the block must wait before any is allowed to proceed.
Shared Memory gives an example of using shared memory.
For efficient cooperation, the shared memory is expected to be a low-latency memory near each processor core (much like an L1 cache) and __syncthreads() is expected to be lightweight.

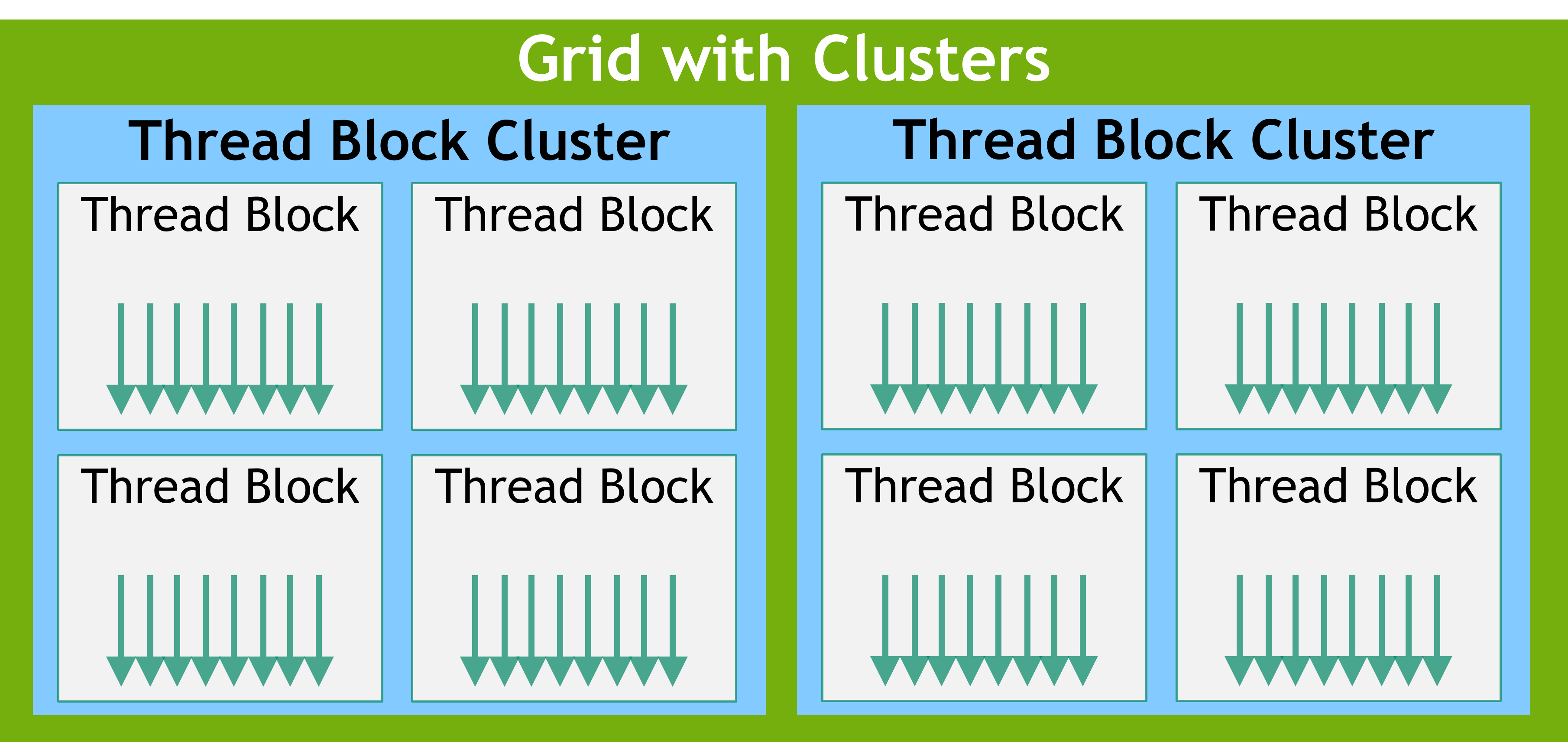
Thread Block Clusters
With the introduction of NVIDIA Compute Capability 9.0, the CUDA programming model introduces an optional level of hierarchy called Thread Block Clusters that are made up of thread blocks. Similar to how threads in a thread block are guaranteed to be co-scheduled on a streaming multiprocessor, thread blocks in a cluster are also guaranteed to be co-scheduled on a GPU Processing Cluster (GPC) in the GPU.
Similar to thread blocks, clusters are also organized into a one-dimension, two-dimension, or three-dimension.
The number of thread blocks in a cluster can be user-defined, and a maximum of 8 thread blocks in a cluster is supported as a portable cluster size in CUDA.
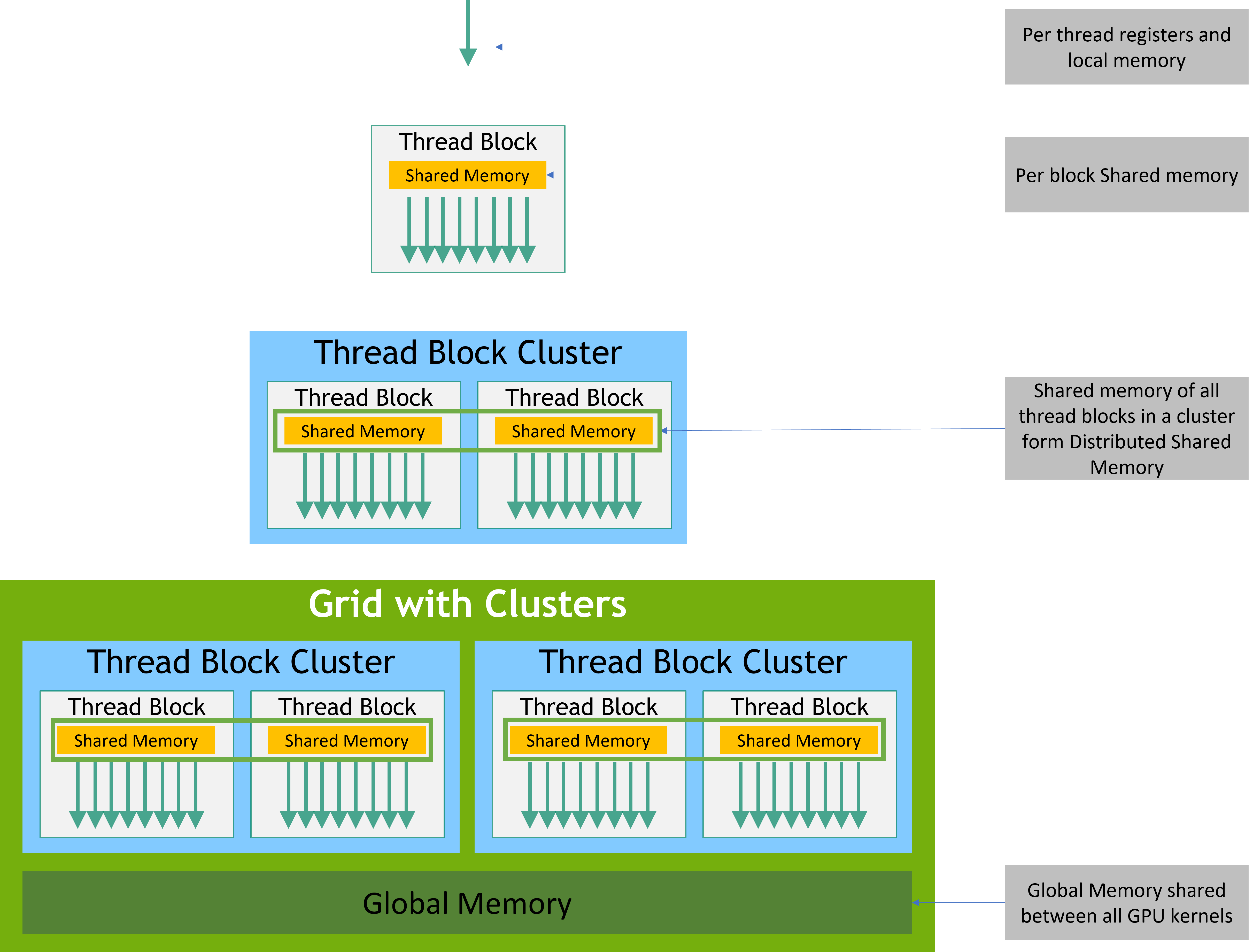
Memory Hierarchy
CUDA threads may access data from multiple memory spaces during their execution.
- Each thread has private local memory.
- Each thread block has shared memory visible to all threads of the block and with the same lifetime as the block.
- Thread blocks in a thread block cluster can perform read, write, and atomics operations on each other’s shared memory.
- All threads have access to the same global memory.