[Weekly Review] 2020/05/04-10
Published:
by
SingularityKChen
![]() (Last updated:
)
(Last updated:
)
- Categories:
- WeeklyReview 81
2020/05/04-09
This week, I polished the Scala model and made it preliminary configurable. Also, I changed the architecture of my final thesis and polished some words.
I prepared for the TPT in NTU at weekends.
From next week on, I'll mainly prepare for the TPT and GRE test, polishing the thesis if needed. If I'm tied or so, I'll improve the Scala modelling test as well, such as writing a mapping function.
High Speed Cache
Different Indexed and Tagged Methods
Virtual Indexed Virtual Tagged
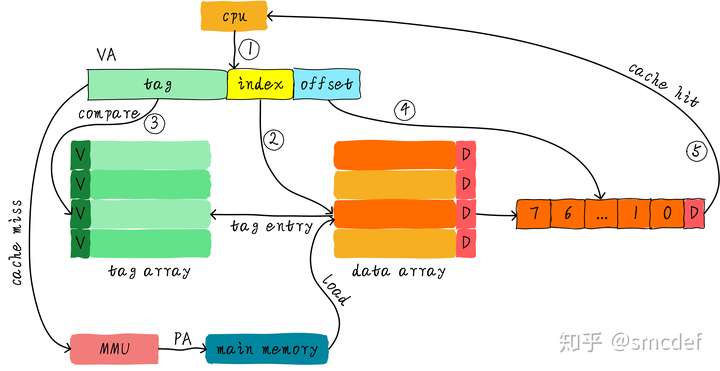
Send virtual address to cache controller. If miss, then send the address to MMU(memory management unit) to translate it to physical address.
Ambiguity
If two different virtual address mapped to the same physical address, we call it ambiguity. Then if thread A uses 0x4000 to map 0x2000 in PA, thread B uses 0x4000 to map 0x3000 in PA, it will occurs error when changing thread A to B.
To avoid that, while we changing threads, we need to flush all the cache. However, it will causes many cache miss at each beginning, leading to low efficiency.
Alias
Alias means different virtual addresses with different index mapped to the same physical address. It will cause trouble while writing one virtual address and reading another.
Physical Indexed Physical Tagged
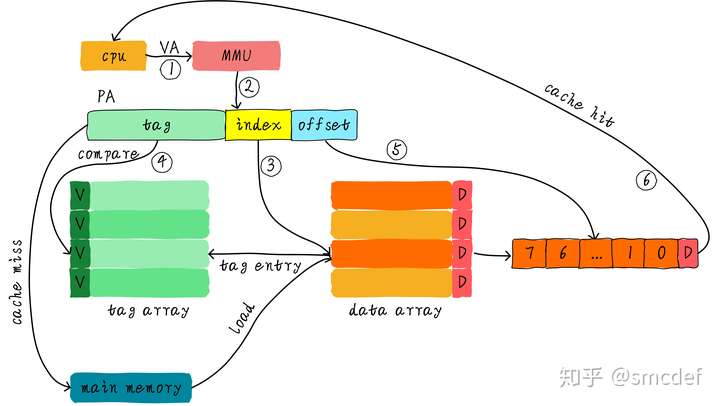
Each virtual address will be translated to physical address in MMU. It can avoid ambiguity and alias problems but cost more in hardware.
Virtual Indexed Physical Tagged
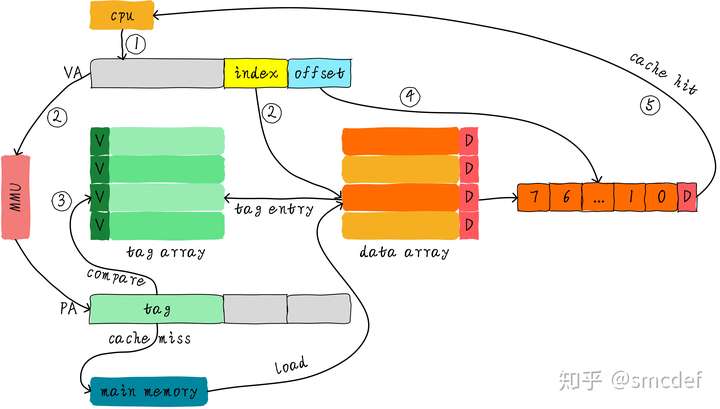
We can use virtual index to look for cache line, meanwhile MMU translates the virtual address. Then comparing the tags of cache line's and physical address's, we can know whether hit or miss.
How to solve VIPT Alias Problem
The indexes of different virtual addresses needed enjoy the same index. For example, 0x0000 and 0x2000 own the same index, 0x00, so even they are mapped to the same physical address, the value will not be stored in more than one cache line.
TLB(Translation Lookaside Buffer)
A common 64-bit system will have four levels page table, named PGD, PUD, PMD, PTE.
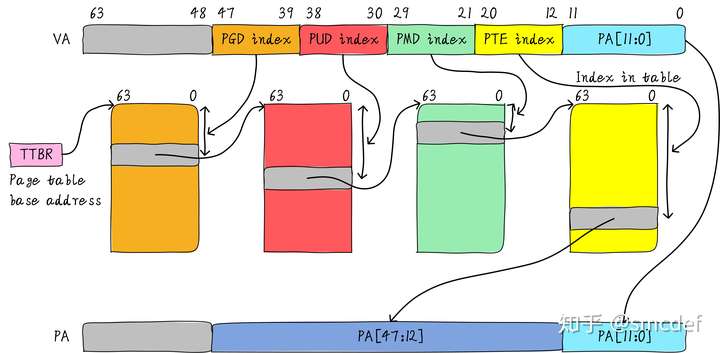
TLB is used to shorten this lookup processing, which stores the physical addresses in the corresponding virtual address.
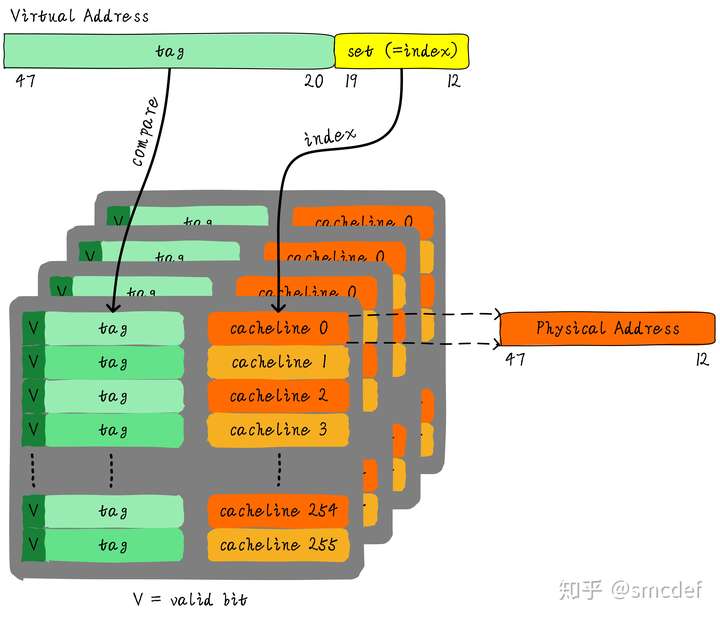
TLB is a VIVT cache without offset.
But to avoid ambiguity, we can add a address space id (ASID) to distinguish different treads' TLB. Then we don't need flush TLB each time.
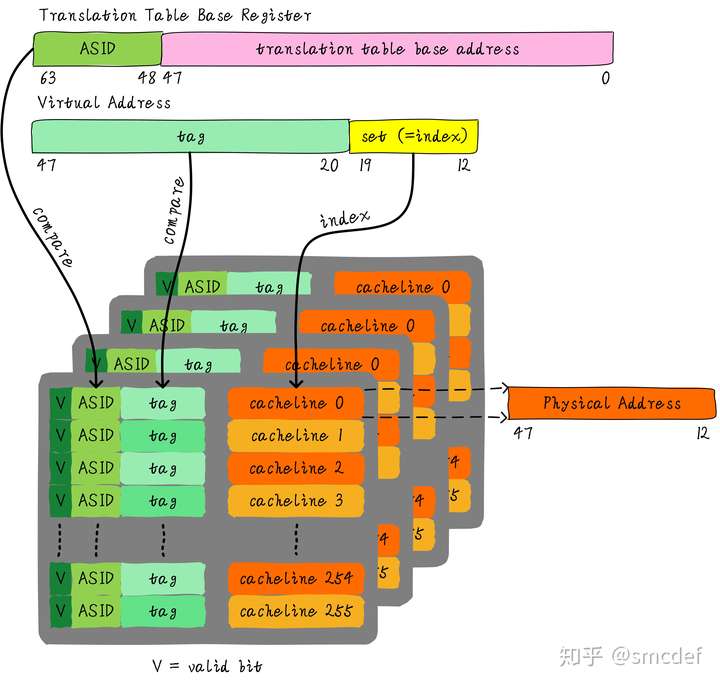
Each time all ASIDs are assigned to one PID, then flush TLB, reassign the ASID.
If two threads using kernel space, where all threads share the same address, then it doesn't need to change the TLB. We can use non-global (bG) bit. If true, then TLB hits.

Cache and DMA Coherence
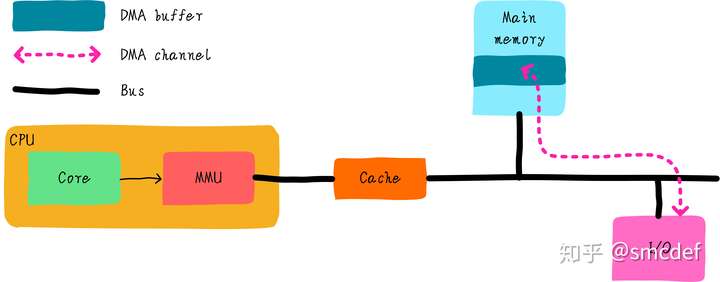
If CPU writes the data in cache, and DMA wants to read the corresponding data in main memory, then it might reads the wrong data.
Nocache
Allocate one area in main memory acts as buffer (4KB minimal). But it will affect efficiency.
Software Maintain
- DMA write back to DMA buffer(in main memory). Invalid All the caches related to the DMA buffer until writing finishes.
- DMA read from DMA buffer. Before read, clean all the cache(write back the changed data). But avoid CPU changes the cache while DMA reading from DMA buffer.
iCache and dCache Coherence

Why need both
To get both instructions and data parallelly. And can reduce hardware cost as iCache is read only.
Coherence
In some special occasion, some codes will correct the instructions at runtime.
- load the old instruction into the dCache
- correct the old one, write the new one back to the dCache
But
- If the old one has been read into the iCache, it will cache hit but get the old one
- If cache miss, the iCache will read from main memory, getting the old one, too
Software Maintain the Coherence
- load the old instruction into the dCache
- correct the old one, write the new one back to the dCache
- clean the corresponding cache line in the dCache, making sure the new instruction will be wrote back to main memory
- invalid the corresponding cache line in the iCache, making sure the instruction will be read from main memory
Multiple Cache Coherence

Bus Snooping Protocol
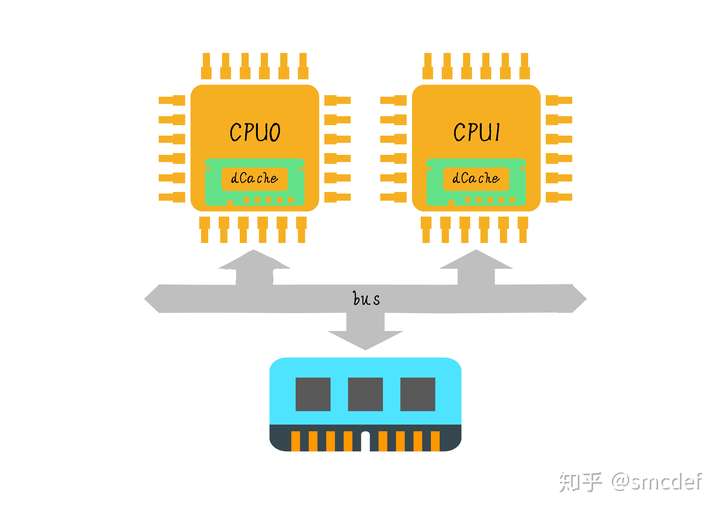
While CPU0 writes the cache, then it will send this information via bus to other CPUs. Then if CPU1 receives this information, it will check whether it loads this data into its cache. If true, then it will update the corresponding cache line.
However, this protocol will increase read/write delay.
MESI Protocol
Every cache line adds a state machine: exclusive, shared, modified, invalid.
While only one cache stored one cache line, then it's exclusive, otherwise shared .
If changes the data, then it becomes modified. Then if it needs flush, it will write back the modified cache line and makes the corresponding cache lines in other CPUs be invalid.
The information only needs to be sent to other CPUs in invalid and shared state.