[Weekly Review] 2020/05/11-17
Published:
by
SingularityKChen
![]() (Last updated:
)
(Last updated:
)
- Categories:
- WeeklyReview 81
- Tags:
- Atomic 1
- FalseSharing 1
2020/05/11-17
This week, I continued on preparing GRE test and waiting for the exact exam date of TPT. Meanwhile, I finished defense slides and an amendment for my FYP thesis.
High Speed Cache
Cache Atomic
If we want to increase one variable twice in two CPUs, then
+ +----------------------+----------------------+
| | CPU0 operation | CPU1 operation |
| +----------------------+----------------------+
| | read counter (== 0) | |
| +----------------------+----------------------+
| | increase | read counter (== 0) |
| +----------------------+----------------------+
| | write counter (== 1) | increase |
| +----------------------+----------------------+
| | | write counter (== 1) |
| +----------------------+----------------------+
V
timeline
But what we need is increase counter twice to 2.
Bus Lock
While the CPU dose an atomic operation, then lock the bus until it finishes to prevent other CPUs change the memory. However, we only care about the address we're operating on.
Cache line Lock(Address Lock)
Implemented via a cache protocol. Most hardware utilizes MESI protocol. While the cache line is Exclusive or Modified, then only current CPU load this data, so we can directly change it.
Meanwhile, this CPU sends Read Invalidate to guarantee the corresponding cache line in other CPUs are invalid, and reload it from current CPU's cache. After operating, unlock the cache line.
If another CPU sends Read Invalidate during this period, then this CPU will check whether the cache line is locked. If it's locked, then this CPU won't send back Invalidate Acknowledge message until it's unlocked.
But this will require the operation is done within one cache line.
LL/SC(Load-Link/Store-Conditional)
The basic idea behind LL/SC is that, instead of guaranteeing forward progress with a load-locked that always succeeds, but which may deadlock, load-linked would employ optimistic concurrency control. Software would assume that it had worked, perform the operation that you want to be atomic, and then try to commit the operation using store-conditional.
If the operation was atomic, i.e. if nobody else had accessed the memory location load-linked, the store-conditional would proceed.
But if the operation were non-atomic, if somebody else had accessed the memory location, the store-conditional would fail. And the user software would be required to handled that failure, e.g. by looping.
fetch-and-add:
L: oldval := load-linked MEM
newval := oldval+a
store-conditional( MEM, newval )
if SC_failed goto L
return oldval
False Sharing

If global_A and global_B are stored in main memory within one cache line size , then they will be read into one cache line.
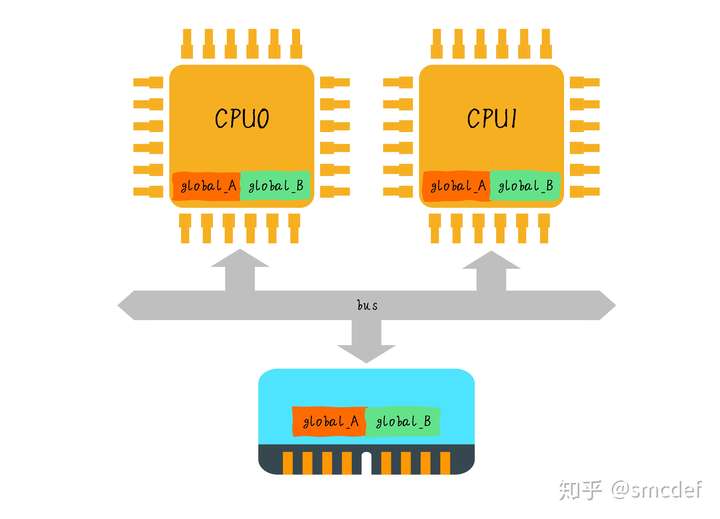
If CPU0 is going to modify global_A and CPU1 is going to modify global_B, then this two values will be translated between this two CPUs again and again, hence wasting time.
But in actual, CPU0 only needs global_A and CPU1 only needs global_B, this names false sharing.
To solve this, store this two variable into two cache line size in main memory.